안녕하세요, 오늘은 CS231N 두번째 강의인 Image Classification 공부를 이어서 해보려고 합니다.
개인적인 공부용으로 블로그를 작성하는 것이며, 인공지능에 대해 알고자 하는 분들에게도 도움이 되었으면 좋겠습니다.
Image Classification(이미지 분류)는 컴퓨터 비전에서 가장 핵심 기술

Image는 기본적으로 숫자(0~255 사이숫자)로 구성된 3D array.

- Challenges
1) Viewpoint Variation (보는 시각)
2) Illumination (조명)
3) Deformation (형태의 변형)
4) Occlusion (은폐/은닉) - 기계가 인식할 수 있겠느냐?
5) Background clutter
6) Intraclass variatioin (고양이 중에서 어떻게 개별 고양이를 구분?)
Image classifier 를 함수로 표현하자면,
image를 인자로 받아서 예측을 하는 결과 값으로는 이미지가 어떤 class에 속하는지 label을 알려주는 것을 return. 이미지를 입력값으로 주고 label을 도출해내는 하나의 함수를 사용했다

*주의 : 어떤 숫자를 정렬하는 것과 같은 알고리즘과는 다르게 고양이 같은 class로 인식하는 하드 코딩하는 알고리즘이 존재하지 않는다. 따라서, 역사적으로 오랜 기간동안 시도가 되어져 왔다.

- 역사적으로 해왔던 시도
아래 이미지의 특징적인 edge나 shape, junction을 찾아서 library화를 하고,
이미지가 어떻게 arrange 되어져 있는지 비교해서 탐색. (여러 특징들을 찾아서 다른 이미지가 들어왔을 때 전반적인 상태를 비교하고 classify를 하려는 시도
한계
scaleable 하지 않은 접근 방법이라 한계 존재

computer vision에서 유명한 Lena
*석사 수업에서도 자주 등장하는 Lena 입니다.
따라서, 한계를 극복하고자 아래의 데이터 기반 접근 방식을 사용 하였다.
- Data driven approach (데이터 기반 접근)
이미지와 레이블로 구성된 dataset을 수집한다. > dataset에 대해 image classifier 학습시킨다 > Test image set에 대해 학습시킨 이미지 classifier를 평가한다.

함수로 표현하자면 Train과 predice 두개의 함수를 가지게 된다. 즉, 학습시기에는 이미지와 레이블을 받아서 모델을 도출해내고, 예측을 할 때에는 모델과 (앞의 트레인 이미지와는 다른) 별도의 텍스트 이미지를 넣어줘서 텍스트 이미지 label을 반환하는 것이 predict 함수의 목적이 된다.
- Data-driven approach의 방법들
- Nearest Neighbor Classifier (더이상 아무도 사용하지 않음. 학습용임)
*Nearest Neighbor : test와 가장 거리가 짧은 training 이미지를 고르는 것
*Non parametric approach라고도 한다. (parameter가 들어가지 않아서)
메모리에 각각의 이미지와 레이블을 기억
예측 단계에서는 테스트 이미지를 모든 트레이닝 이미지 하나하나와 비교를 함으로써 가장 비슷한 트레이닝 이미지 레이블을 이 테스트 이미지 레이블 이라고 예측을 하게 된다.

TEST) 테스트 데이터는 아래와 같다.
레이블 10개, 6만 이미지( 5만은 트레이닝, 1만은 테스트) 32*32 픽셀

파란색 상자는 테스트 이미지이며, 바로 옆 10개는 가장 비슷한 이미지를 묶은 것이다.
- 어떻게 동작하는지 알아보자면
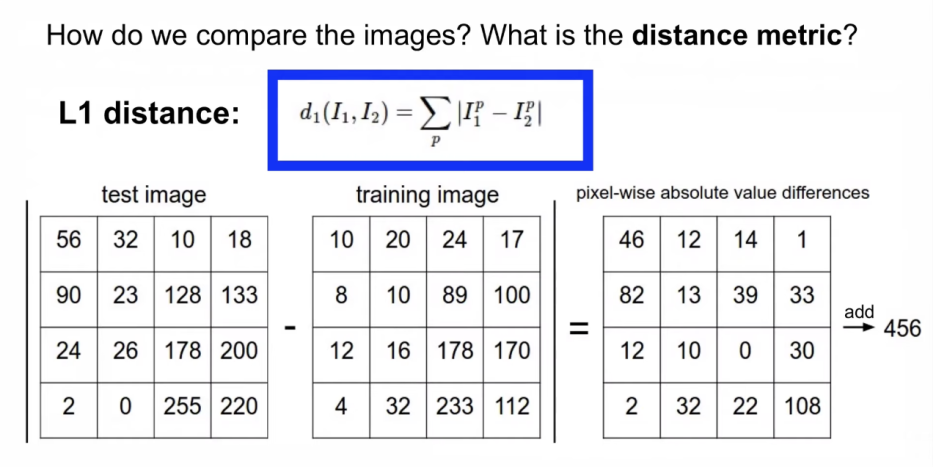
Test 이미지를 모든 training set 이미지 하나하나와 각각 비교한다고 했는데 그 비교하는 기준은 Distance(거리)
여기서는 L1 distance(=Manhattan distance) 사용. 이미지1과 이미지2의 차이에 절대값을 씌워준 형태
test image - training image = 456 (456이라는 거리를 보인다는 뜻)
- 코드로 표현하자면
Train 함수 : 그냥 assign 해줌으로서 기억

Predict 함수 : 여기서 x는 테스트 이미지
핵심은 distances 한줄( 5만개의 트레이닝 이미지들과 비교함으로 L1 distance를 계산.
*한줄로 가능한 이유는 numpy에서 제공하는 broadcast같은 기능이 있어서

L1 distance 기준으로 해당 test이미지와 가장 가까운 즉, L1 distance가 가장 작은
train set중의 이미지를 찾는 것이 된다.
따라서, test 이미지의 label을 예측을 할 수 있게 되는 것이다.
Q: how does the classification speed depend on the size of the training data?
A: linearly하게 증가한다. (training data가 2배가 늘어나면 분류작업 시간도 비례해서 2배로 늘어난다.)
이유: 메모리 상의 트레이닝 이미지와 레이블을 모두 올려놓고 각각에 대해 distance를 살펴보기 때문이다.
test 속도 빠른게 중요한데 여기서는 그렇지 못하다 (convolutional neural network 에는 반대이다. 1000개이든 100개이든 테스트 때에는 일정한 시간이 소요된다.)
This is backwards :
- test time performance is usually much more important in practice.
- CNNs flip this : expensive training, cheap test evaluation.
L2 distance도 존재한다. 어떤 것을 사용할 것인지는 하나의 hyperparameter
주어진 환경에서 여러번의 실험을 통해 최적의 파라메터를 찾아야 된다는 의미에서 hyperparameter라 할 수 있다.

2. KNN (K-Nearest Neighbor)
K개의 가장 가까운 이미지를 찾고, 이 K개의 이미지들이 다수결로 voting을 한다.
좀 더 부드럽게 Classification한다.

가운데 : NN / 오른쪽 : K가 5인 Knn
Q: what is the accuracy of the nearest neighbor classifier on the training data, when using the Euclidean distance?
A: 100%
이유 : 테스트한 트레이닝 데이터와 동일한 이미지가 이미 트레이닝 set 내에 존재하기 때문에 distance가 0이 된다. 동일한 이미지를 비교하니까(자기 자신과 비교하는 셈)
여기서는 Euclidean distance로 물어봣는데 manhattan을 써도 동일하다.
Q: what is the accuracy of the k-nearest neighbor classifier on the training data?
A: Not necessary (상황에 다르다)
이유 : 1위는 무조건 정확하게 class를 예측하지만, 2위3위4위5위가 엉뚱하게 예측하면 다수결에 의해 순위가 바뀔 수 있기 때문이다.
What is the best distance to use? (L1 distance와 L2 distance 중에 어떤 것을 사용해야 할까)
What is the best value of k to use? (KNN이라면, K를 5? 1? 2? 뭐를 써야할까)
how do we set the hyperparameters? (이런 것을 결정할 때 우리는 이러한 것들을 hyperparameters라고 알고 있는데 어떻게 설정해야 하는가?)
>> Very problem-dependent. Must try them all out and see what works best.
hyperparameters 설정은 문제에 따라 다르게 된다. 따라서, 주어진 환경에서 각각의 파라메터들을 실험해보고
그 중에서 가장 performance가 잘나오는 hyperparameter 설정하기.
그렇다면, Trying out what hyperparameters work best on test set(하이퍼파라메터를 계속 바꿔가보면서 test set에 적용하면 되나?)
A : No. Very Bad idea. The test set is a proxy for the generalization performance! Use only Very sparingly, at the end. (테스트 셋은 성능평가를 위해 끝까지 남겨둬야 하는 데이터 셋이라 함부로 쓰면 안됨)

따라서, hyperparameters를 설정하기 위해 여러번 실험을 해야하기 때문에 Validation data를 마련한다.
training data에서 일부분 (약 20%)을 떼어서 hyperparameters를 튜닝하기 위한 공간으로 사용

때로는 Training data의 수가 적은 경우가 있는데 이러한 경우에는 Cross-validation 활용
즉, 1,2,3,4번에서 트레이닝을 하고 5에서 validation하고 나서는 2,3,4,5번에서 트레이닝을 하고 1번에서 validation 하는 식으로 5번 반복한다.

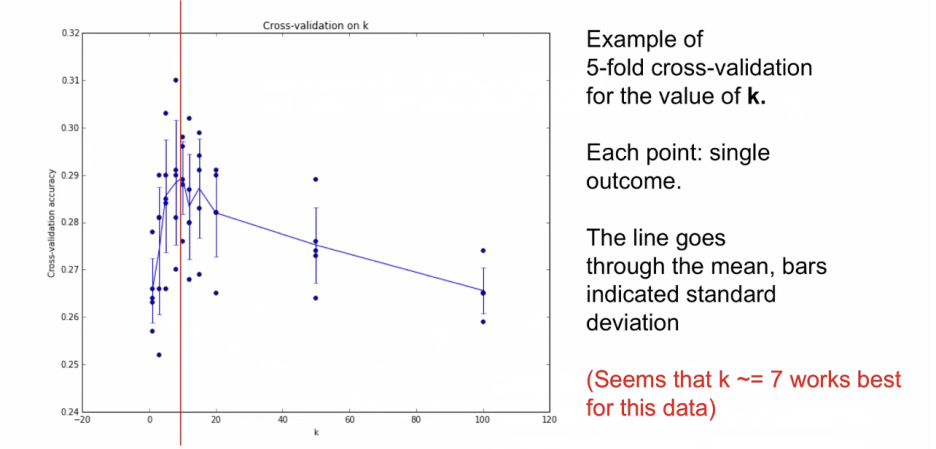
아래의 그래프는 각각의 K에 대해 5fold cross validation을 했을 때의 정확도를 보여준다.
5개의 평균을 보여주는 것이 실선이다. 평균값이 가장 높은 것을 보면 7정도가 평균 값이 가장 높다.
따라서, K가 7일 때가 평균값이 가장 높은 것으로 볼 수 있다. K가 7인 경우에 가장 높은 정확도를 보인다.
KNN에서 K가 hyperparameter인데 이것을 7로 설정한다.
*Nearest Neighbor은 현실에서 사용하면 절대 안된다.
이유
1) Test time 성능이 매우 안좋다.
2) Distance가 현실적으로 예측하기 어렵다.
아래를 보면 3개의 이미지는 다른 이미지인데 동일하게 판단한다.

요약은 아래 참고

Linear Classification
(Convolutional neural network로 가는 시작점)
Neural Network는 흡사 레고를 쌓아가는 과정

나중에는
이미지 캡셔닝 모델도 공부하게 되는데
이미지 캡셔닝 : 해당 이미지에 있는 object들을 classify한 다음에 text로 표현을 해주는 것.

CNN과 RNN이 결합되어서 마치 하나의 네트워크처럼 동작한다.
CNN으로 classify하고 RNN으로 문장을 구성한다.

*RNN : 시퀀스 처리에 강한 문장 혹은 목소리 혹은 동영상같은 시퀀스의 처리에 강점을 가지고 있는 network
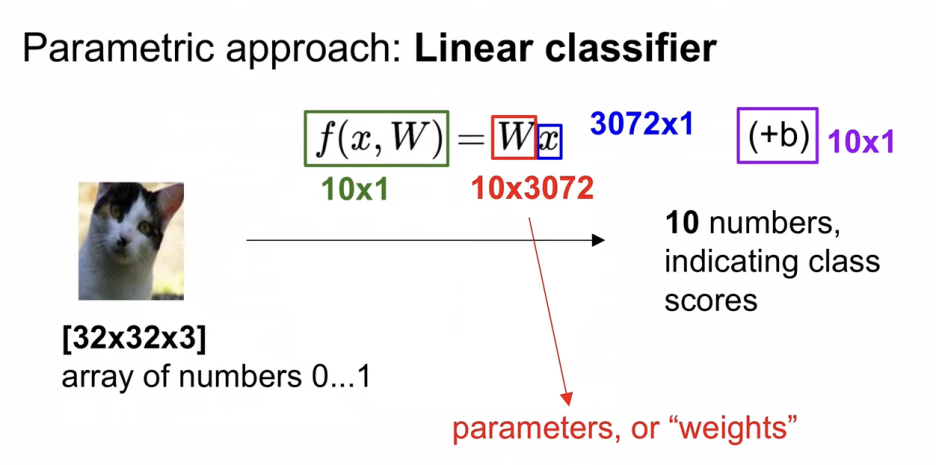
Nearest Neighbor과는 다르게 parametric approach 방법이다.

이미지인 x는 컨트롤 할 수 없다.
parameters인 W는 컨트롤 할 수 있다. 따라서, 3,072개의 이미지가 input으로 입력되었을 때,
출력값으로 10개의 숫자를 return해주는 방식을 취하고 있다.
32*32*3을 쭉 펼쳐서 이미지는 3,072 by 1 column vector가 될 것이다.
결과적으로 총 3만 7백 20개의 Weights가 될 것이다.

Bias 값도 Parameter 값이기 때문에 최적값을 찾아내야 한다.
4개의 픽셀만 가진 이미지라 가정 : 4 by1 column vector
3개의 class만 가정 : 3 by 1 column vector
bias도 마찬가지로 : 3 by 1 column vector
>> 따라서, x가 4 by1, score가 3 by 1 일 때 우리는 w를 3 by 4로 맞춰줘야 한다.

이제 행렬 연산을 해준다.
{(0.2*56) + (-0.5*231) + (0.1*24) + (2.0*2)} - 1.1 = - 96.8 ( 고양이의 스코어 )

> 고양이의 점수가 매우 낮게 나왔으니, 우리 모델은 아직까지 학습이 되지 않아 성능이 매우 저조한 상태

Q: what does the linear classifier do, in English?
A:
1) 이미지 내의 모든 pixel 값에 대해서 가중치를 곱하여서 처리한 것의 합이다.
Just a weighted sum of all the pixel values in the
2) 각각 다른 공간적 위치에 있는 컬러들을 counting 한 것이다.( color가 매우 중요하다)
Counting colors as different spatial position

Color가 매우 중요하다고 했는데, 여기서 보면 학습한 가중치들(Linear Classifier)을 시각적으로 표현을 해보니
아래 파란색처럼 나온다.
말을 보면 왼쪽과 오른쪽 말들이 있으니 흐릿하게 보이고,
개구리를 보면 갈색과 노란색을 띄고 있는데
노란색 자동차인 경우에는 차로 classify를 정확히 하기 보다는 개구리로 판별할 문제가 생길 수 있다.
결론적으로 Linear Classifier 만을 적용했을 경우의 결과는 좋지 않다.

Linear Classifier를 해석하는 또다른 방식은 "공간"이 있고,
그 공간을 각각의 Classifier로 분할한다.

Q: what would be a very hard set of classes for a linear classifier to distinguish?
A:
1) 사진에서 negative film( 정반대의 색상 네거티브 처리하는 것)은 형태 인식은 되지만 color은 정반대로 되니까 구분이 어려워 질 것이다. 그리고 gray 색상의 이미지들은 color가 기준이 아니라 texture나 detail 기준으로만 봐야되니 성능이 떨어질 것이다.
2) texture가 형태는 다르지만 color는 동일한 경우에는 분간하기 어려울 것이다.
반대로, 강아지가 가운데 있건 왼쪽에 있건 아래에 있건 쉽게 구분을 할 것이다.

지금까지 우리가 한 것은 Score function을 정의한 것이다, 즉, Linear classifier를 이용해 Score를 낸 것이다.
자동차는 잘되었고, 대신 개구리는 매우매우 안되었다.
Loss function을 정리를 해야된다.
나온 결과의 score가 어느정도 좋거나 나쁘거나를 정량화 하는 것

이미지를 score function을 이용해 score로 만들었고,
앞으로는 loss function을 이용해서 score를 loss로 만들어보려 한다.
'7. 수학공부 > 기타' 카테고리의 다른 글
| Lecture 5 Training Neural Networks, Part I (1) | 2024.12.06 |
|---|---|
| Lecture 5 Training Neural Networks, Part I (0) | 2024.12.06 |
| Lecture 4 Introduction to Neural Networks (3) | 2024.12.05 |
| Lecture 3 | Loss Functions and Optimization (0) | 2024.12.03 |
| CS231N, Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition (0) | 2024.11.30 |