신경망을 어떻게 학습시키는지 알아보려 합니다.
오늘은 분량이 많아 데이터전처리 전단계까지 리뷰하겠습니다.
지난시간 학습내용 정리
ConvNets need a lot of data to train 이라고 생각하는데 어쩌면 잘못된 생각일 수 있다
왜 ? finetuning 방법이 있어서이다. 즉, we rarely ever train ConvNets from scratch.
(우리는 우리 모델을 처음부터 학습시키는 경우가 별로 없다.)

다시 말해서, 이미지넷의 데이터를 기반으로 학습시키고 우리는 이미 학습된 가중치를 가져와서 이 가중치를 우리 데이터에 finetuning 시킨다.

우리는 가운데 그림에서처럼 우리가 가지고 있는 데이터셋이 작으면
기존의 이미지넷에서 학습한 모든 가중치를 그대로 고정시킨다.
그리고 마지막부분의 classifier부분만 트레이닝 시키는 것이다. Softmax layer만 교체해준다.
또는 마지막 그림처럼 데이터셋이 아주 작지도 충분하지도 않은 경우에는 finetune을 한다.
방법1) 이미지넷에서 학습시켜서 가져온 가중치들을 새로운 모델의 초기화 값으로 사용하는 것이다. (initialization value로 사용하는 것이고, 이것을 기반으로 전체 network를 학습시키는 것)
방법2) 위쪽부분은 fix를 해놓은 상태에서 아래 부분만 새로 학습시키는 것이다.

다양한 데이터 셋에 대해 학습을 시킨 가중치를 사람들이 업로드를 해준다.
대부분의 경우에 우리는 처음부터 학습시킬 필요가 없고
가중치 기반으로 데이터를 얹어서 파인튜닝을 하게 된다.

무리하게 많은 데이터를 돌릴 생각을 하지 말아라!

Mini batch SGD :
데이터에서 샘플링(128, 256 데이터 선택) > Forward를 통해 Loss를 구하고 > Backpropagation통해서 gradient를 구하고 > 구해진 gradient를 기반으로 parameter 업데이트를 해준다.
이것을 다음 batch에 대해 진행하는 식으로 반복한다.
마치, 산에서 눈을 가리고 최적의 경사를 찾고 내려오는 것과 유사하다.
찾아가는 과정은 여러가지가 있는데 local gradient와 global gradient를 구해서 chain rule에 의해 gradient를 구하는 것에 알아보았고, 코드도 살펴보았다.
ex) torch layer에서 Neural Network를 학습했고, 생물학적 뉴런과 인공지능 뉴런과 구조에 대해 학습했다.
Training Neural Networks
1. 역사

1957년 Perceptron이 최초
Mark | Perceptron : 서킷기반 함수
activation function이 minary step function이라 미분이 불가(미분이 불가능하다는 것은 backpropagation불가) 따라서 가중치(w)값들을 조절해가면서 network 최적화. 즉, W들을 임의 조정하면서 최적화를 실시한 것이다.

1960년 Perceptron을 스테킹 (쌓아가기 시작함)
이때도 backpropagation은 불가했다.

1986년 최초로 backpropagation도입. (미분이 가능하다는 것이고 가중치(w)를 체계적인 방법으로 찾아갈 수 있게 되었음)
network이 커지고 deep 해지면 동작을 잘 안했다.

2006년에 되어서야 제프리 힐튼 교수에 의해 backpropagation이 잘 동작하게 됨.
RBM(Restricted Boltzman Machine)을 통해 별도로 unsupervised된 pre training(선행학습)을 함..
첫 단계(pretraining) : 각 단계에서 RBM을 학습시킨다. 30개 500개 1000개를 각각 선행학습 시키고
두번째 단계(Unrolling) : 실제로 이들을 큰 덩어리로 묶고 backpropagation으로 묶으니 잘 동작하고,
세번째 단계(Fine-tuning) : 이들을 fine tuning 해주는 식으로 진행
별도로 RBM을 이용해 pre train을 해야할 필요가 없었다는게 나중에 밝혀졌다.
밝혀진 이유 : 1) 가중치 초기화 (initialization에 문제가 있었고),
2) sigmoid함수를 activation함수로 쓴것이 문제가 있었다.

2010년 (마이크로 소프트)과 2012년 (힐튼교수)
Deep learning이 폭발적으로 성장함
Weight initialization을 잘할 수 있는 방법을 찾았고, Sigmoid 외에 제대로 된 activation을 적용할 수 있게 되었고, GPU를 원활하게 사용할 수 있게 된점, 데이터가 폭발적으로 늘어난 점이 복합작용하게 되었다.
2. 신경망 학습

1) Activation Functions

정의 : cell body의 linear한 단순 합에 f라고 되어있는 function(non linearity) 제공하는 형태

다양한 것들이 있다.
Sigmoid function

최근에는 사용하지 않는 Sigmoid (넓은 범위의 숫자를 0과 1 사이의 숫자로 Squash해주는 것)
마치, 0과 1사이의 확률과 같이 나오기 때문에 "들어오는 입력 값에 대해 가중치 영향력을 주기에 가장 적합하게 되어있는 점" 때문에 많이 사용함
사용하지 않는 이유
1) 뉴런이 포화되어서 Gradient를 없애버리는 문제점이 있다. (Vanishing Gradient)
Gradient가 0이 되어 사라지게 되는 것을 말함


Vanishing Gradient가 발생하는 이유
gradient = global gradient * local gradient
x가 매우 큰 값을 가지게 되는 경우 : x에 대해 sigmoid 함수를 미분하게 되면 기울기가 거의 0이 되고
x가 매우 작은 경우(-10)에는 기울기가 거의 0이 된다.
즉, x의 값이 작거나 큰 경우에 local gradient 값이 꽤 작거나 큰 경우에는 local gradient가 0이라는 값을 가지게 되므로 gradient가 없어진다(backpropagation이 stop되는 결과가 나온다.)


2) Sigmoid의 결과가 zero-centered가 아니다. (slow 컨버전스를 가져오는 단점)
이 함수를 w에 대해 미분을 하게 되면 xi는 무조건 양수가 됨.
편미분 형태로 분해하면 xi는 dL/dF*xi로써 양수가 된다.
모두 양수라면 모두 양수, 음수라면 모두 음수여야 된다.
즉, w의 gradient는 모두 양수이거나 모두 음수여야 된다.

모두 양수 또는 음수이므로 지그재그로 이루어져 매우 느리게 convergence가 도출됨.
따라서 컨버전스가 느려질 수밖에 없다.
3) exp()가 매우 비싼 함수이므로 성능의 저하를 가져올 수 있다.
3가지 이유로 현재는 거의 사용하지 않는 activation function이다.
tanh(x) function

-1과 1 사이에 squash하는 형태로 zero centered (가운데가 0)
문제점 : x의 값이 매우 작거나 큰 경우에는 여전히 df/dx = 0이 되어 saturated 된다.
ReLU function

현재 activation function을 하나 선택하라고 한다면 default는 ReLU가 된다.
x가 양수인 지점에서는 saturation 발생하지 않는다. 기울기가 1이 되기 때문에 연산이 매우 효율적이고,
sigmoid나 tan(h)에 비해 6배 빠른 convergence를 보인다.
문제점 :
1) zero centered가 아님, x가
2) x가 0보다 작을 때, gradient 값은 0이 된다.(기울기가 0이기에)

x가 10인 경우에는 기울기가 1이 된다.
x가 -10인 경우에는 기울기가 0이 된다. (0보다 작을 때 기울기 0이 되서 vanishing gradient 된다.)
x가 0인 경우에는 미분이 불가능한 경우이기 때문에 기울기가 undefined된다.

뉴런이 데이터 클라우드 내에서 activation 된 경우에는 active ReLU
데이터 클라우드 외부에서 activation 된 경우에는 dead ReLU가 된다.
dead ReLU가 발생하는 경우 (10~20%)는
1) w를 초기화 할 때 운이 나빠서 dead ReLU에서 시작하는 경우가 있고,
2) 학습을 시킬 때, Learning rate (알파)가 너무 큰 경우에 발생. 뉴런의 값이 조금씩 변화를 하다가 가끔씩 dead ReLU 존으로 나가서 안으로 들어오지 못해서 활성화할 수 없는 경우가 생긴다.
>>training을 시킬 때 learning rate을 너무 크게 잡은 경우에 생긴다.
따라서, 0.01 정도 값으로 초기화를 해서 dead ReLU 방지 (양수를 출력하고 업데이트해서)
도움이 될 수도, 도움이 되지 않을 수도 있다.
Leaky ReLU function

2013년도에 카이밍 헤가 Leaky ReLU 주장
렐루와의 차이점 : max의 앞부분이 0이 아닌 0.01x라는 점
0보다 작은 부분에서 기울기가 0이 아닌 기울기를 가지는 형태가 된다.
그렇기에 x가 0보다 크냐 작느냐에 따라 saturation이 발생하지 않을 것이고,
그러다보니 gradient가 죽는 경우가 발생하지 않는다.
ReLU보다 좋을 수도 있지만 검증이 끝난 것은 아니기에 고려해봐야함
PReLU max의 앞 부분이 0.01 대신에 알파.
기울기 대신에 backpropagation을 통해 학습.
알파가 0이라면 랠루와 동일 0.01이라면 리키랠루와 동일한 형태가 되겠지만,
알파라는 것에도 학습을 하겠다는 것이 특징
ELU function(일루)
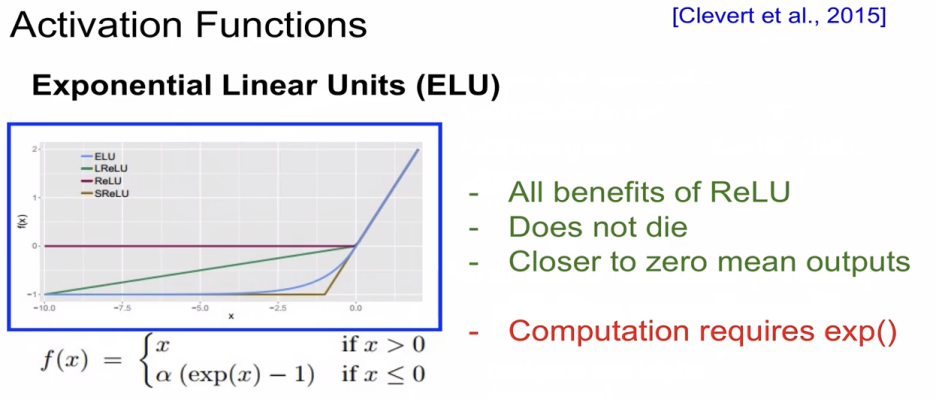
Exponential을 해서 둥근형태가 나타난다.
ReLU의 모든 장점을 가지며, Gradient가 죽지 않고 zero에 가까워 진다는 장점이 있다.
단점은 exponential 연산이 비싼 연산이라 연산(계산)하는데 무리가 갈 수 있다.
"Neuron" function(일루)

뉴런이 연산하는 내용과 방법을 완전히 바꾸는 내용이다.
완전 새로운 방법으로 ReLU와 Leaky ReLU를 일반화하는 내용이면서 saturation도 발생하지 않고, gradient도 죽지 않는 장점이 있다.
단점은 w1과 w2라는 두개의 파라메터 값을 가지게 되므로 연산이 두배로 증가해야 한다.
정리

특별한 경우가 없으면 ReLU
실험이 필요하면 Leaky ReLU / Maxout / ELU
tanh는 사용하지 말고
sigmoid는 더이상 사용하지 않음
'7. 수학공부 > 기타' 카테고리의 다른 글
| [U of T.Reinforcement Learning] Q-Learning, Greedy, exploration, exploitation, discount factor, 그리디, 탐색, Q-러닝 (1) | 2025.01.14 |
|---|---|
| Lecture 5 Training Neural Networks, Part I (1) | 2024.12.06 |
| Lecture 4 Introduction to Neural Networks (3) | 2024.12.05 |
| Lecture 3 | Loss Functions and Optimization (0) | 2024.12.03 |
| CS231 Lecture 2 | Image Classification (1) | 2024.12.02 |