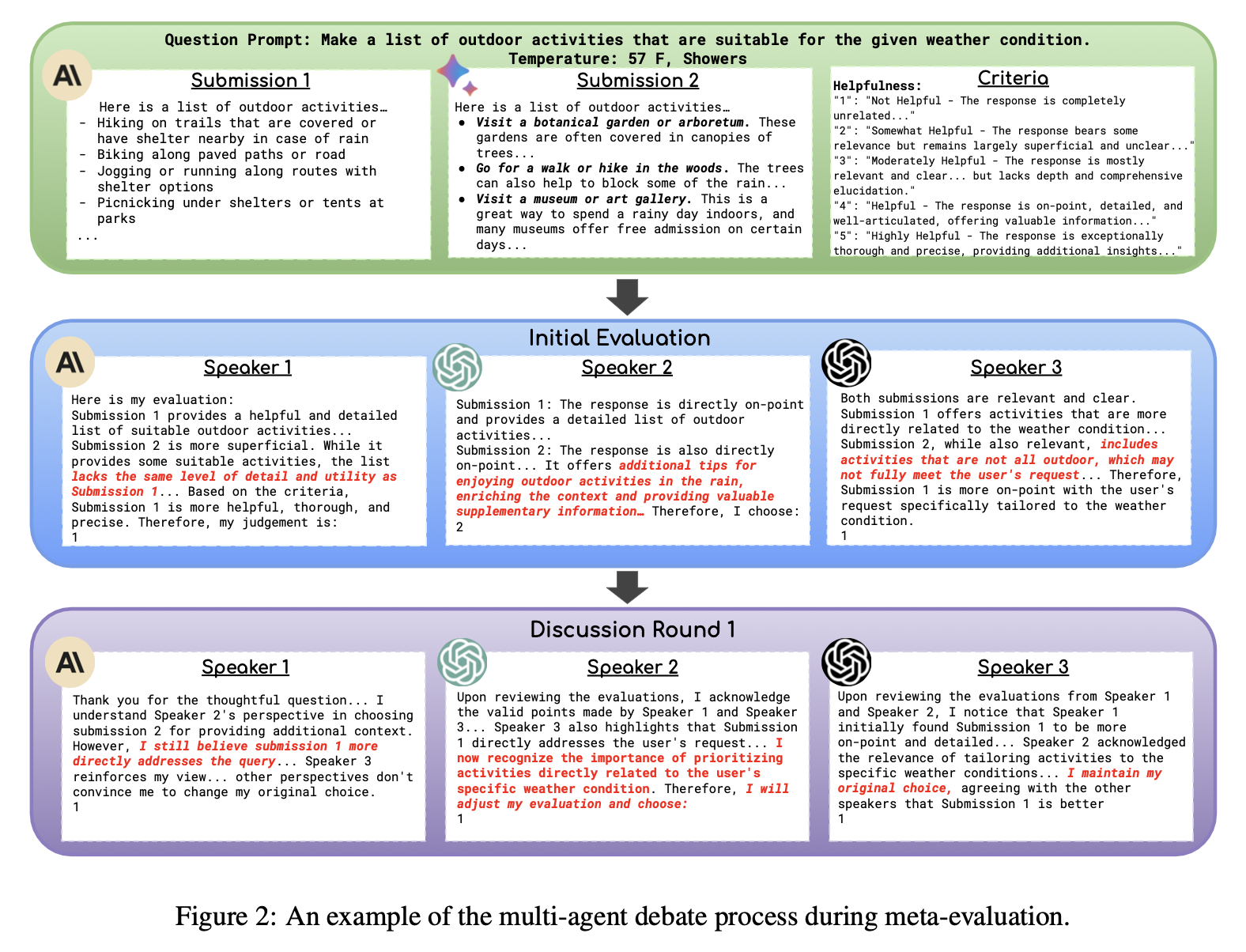
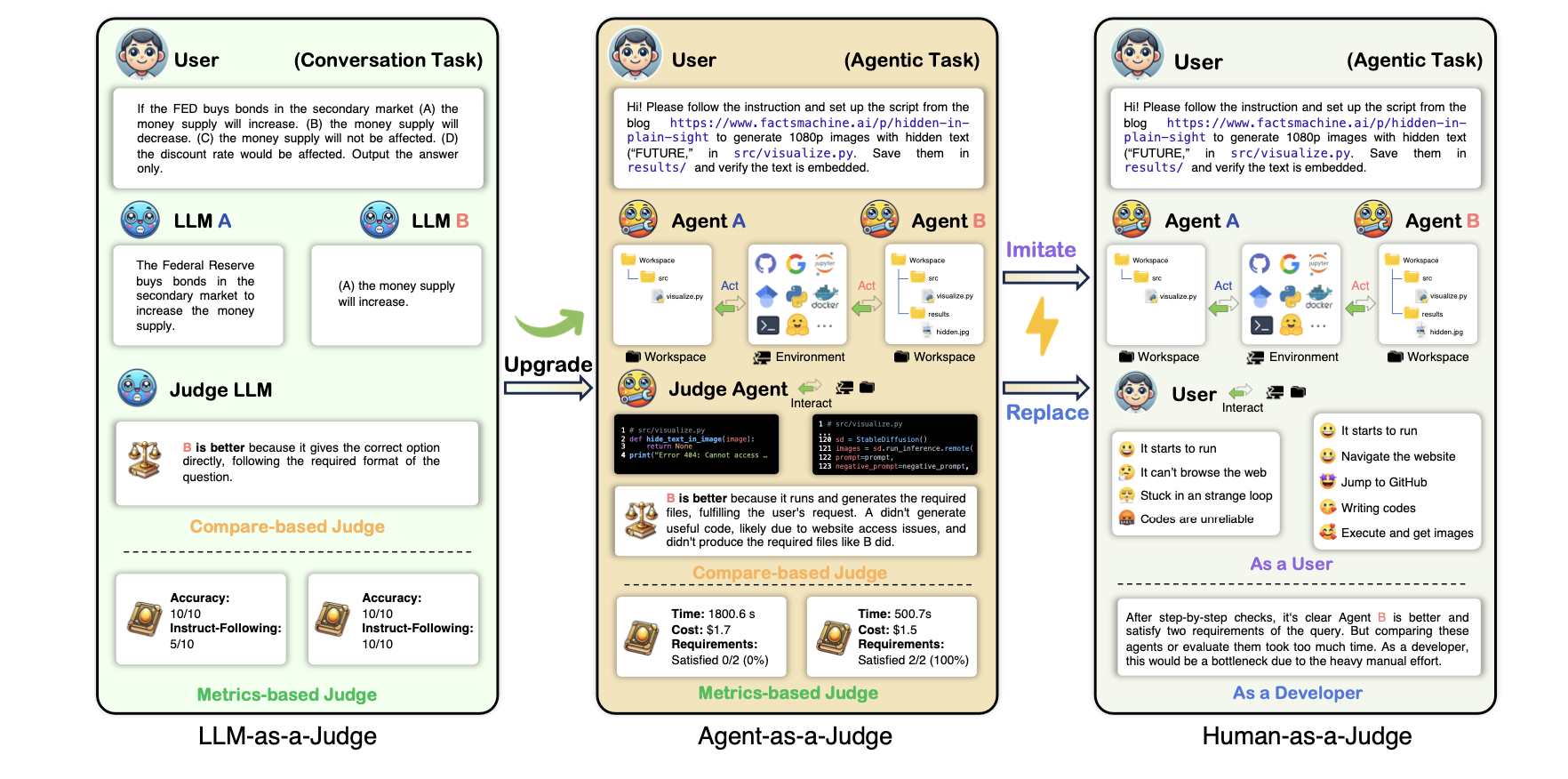
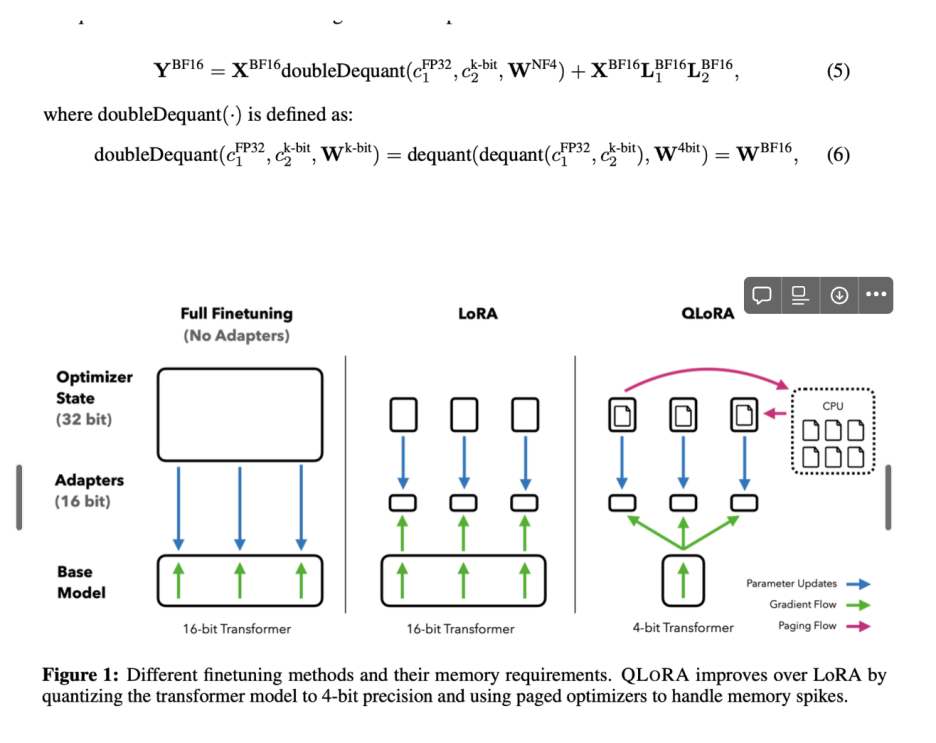
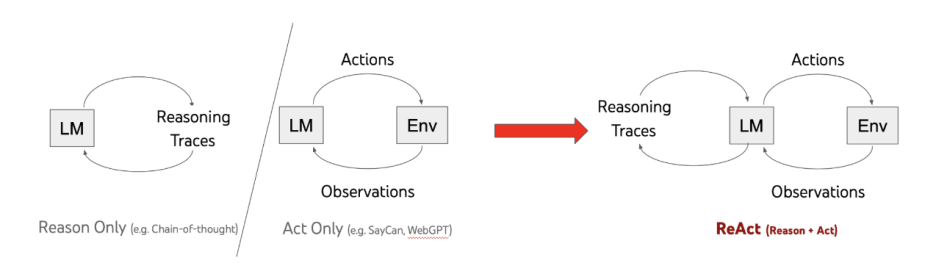
Abstract대형 언어 모델(LLM)은 다양한 작업과 상황에서 유용하게 활용되고 있지만, 이를 신뢰할 수 있는 방식으로 평가하는 방법을 개발하는 것은 여전히 어려운 과제이다. 현대의 평가 방법들은 종종 LLM을 이용하여 다른 LLM이 생성한 응답을 평가하는 방식에 의존한다. 그러나, LLM을 평가자로 활용하는 방식의 효과성을 평가하기 위한 메타 평가(meta-evaluation)는 기존 벤치마크의 한정된 범위에 의존하거나, 광범위한 인간 주석이 필요하다는 문제를 안고 있다. 이러한 한계를 극복하기 위해, 우리는 다양한 작업과 사용자 정의된 새로운 시나리오에서도 LLM의 평가 성능을 효과적이고 신뢰할 수 있으며 효율적으로 평가할 수 있는 확장 가능한 메타 평가 방법이 시급히 필요함을 강조한다.이를 해결하..