안녕하세요,
오늘은 QLoRA (Quantized Low-Rank Adapter) 에 대해 간단하게 리뷰해보도록 하겠습니다.
QLoRA는 파라미터 효율적 미세 조정(PEFT, Parameter-Efficient Fine-Tuning)을 위한 방법 중 하나로, 대형 언어 모델(LLM)을 저비용으로, 더 적은 자원으로 미세 조정하기 위해 설계되었습니다.
특히 FP4(4-bit 부동소수점) 양자화와 낮은 Rank 어댑터(Low-Rank Adapter)를 결합하여 효율성과 성능을 극대화합니다.
그렇다면, LoRA와 QLoRA의 차이가 무엇일까요?
- LoRA는 기존 모델의 일부 파라미터만 저랭크 형태로 미세 조정하여 메모리와 연산 비용을 줄이는 방법이고,
- QLoRA는 LoRA에 4비트 양자화를 추가하여 더 적은 메모리와 낮은 비용으로 비슷한 성능을 유지하는 방법입니다.
LoRA와 QLoRA 비교

어떤 환경에서 LoRA와 QLoRA 중 한가지를 선택해야 할까?

지금부터는 QLoRA 논문의 간단한 Introduction과 QLoRA Finetuning, 성능비교로 마무리하겠습니다.
Introduction
Finetuning large language models (LLMs)은 성능을 향상시키기 위한 가장 효율적인 방법이지만, expensive 하다는 단점이 있다.
따라서, QLoRA는 성능을 희생시키지 않으면서 Memory 사용을 줄이도록 설계된 다양한 혁신 기술이 있다. (QLoRA는 Memory 사용량을 크게 줄이는 효율적인 파인튜닝 접근법으로, 전체 16비트 파인튜닝 성능을 유지하면서 48GB GPU에서 650억개의 매개변수 모델을 파인튜닝 할 수 있다)
QLoRA Finetuning
(1) 4-bit NormalFloat, 4-bit Integers and 4-bit Float 보다 나은 경험적 결과를 제공하는 정규분포 데이터에 대한 정보 이론적으로 최적화된 양자화 데이터 유형(양자화..)
기존의 bin에 걸쳐 값의 불균일한 분포를 초래하는 전통적인 양자화 방법과는 다르게, 각 양자화 bin이 input tensor에서 할당된 동일한 수의 값을 갖는 분위수 양자화이다.
이 방식은 사전 훈련된 모델을 4-bit 양자화하여 큰 매개변수 모델을 fine-tunning하는데 필요한 메모리 요구사항을 크게 줄일 수 있기에 유용하다.
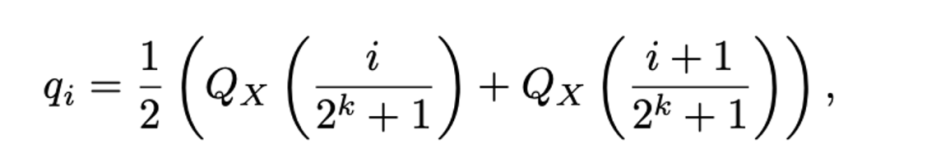
(2) Double Quantization, 매개변수 당 평균적으로 약 0.37bit를 절약하여 양자화 상수를 양자화하는 방법으로 메모리 설치 공간을 줄일 수 있다.
따라서, 매개변수 당 메모리 설치 공간이 크게 감소하므로 복잡한 모델 처리할 수 있다는 장점이 있다.
(3) Paged Optimizers, NVIDIA 통합 메모리를 사용하여 긴 시퀀스 길이의 미니 배치를 처리할 때 발생하는 메모리 스파이크의 기울기 검사를 방지한다.
따라서, 제한된 resource로도 처리할 수 있도록 큰 모델을 단순화하는데 장점이 있다.
(4) QLoRA, 양자화된 base 모델 single linear layer에 단일 LoRA adapter로 QLoRA를 구현할 수 있다. fine-tunning 시 메모리 요구사항을 줄여 단일 GPU에서 큰 모델을 미세 조정할 수 있다.
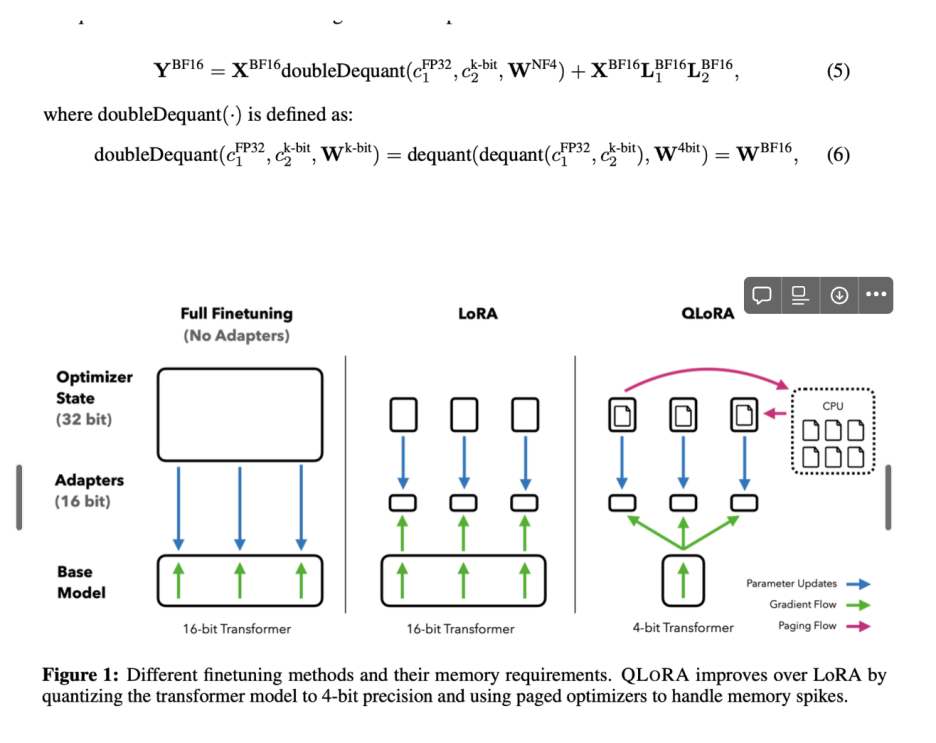
QLoRA vs Standard Finetuning
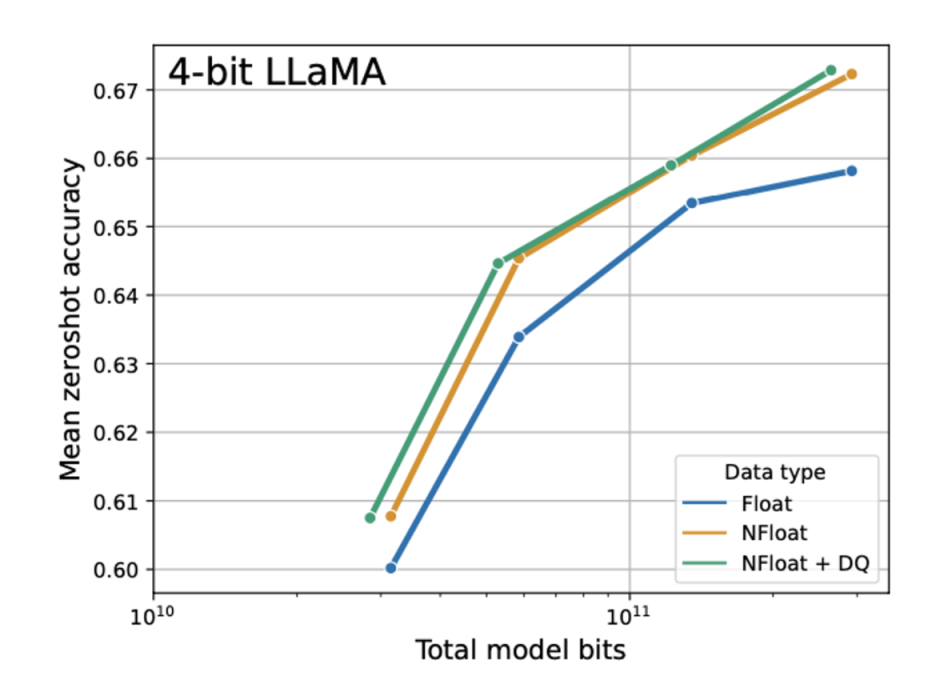
4-bit NormalFloat yields better performance than 4-bit Floating Point
4-bit normalfloat이 성능이 더 좋다.
QLoRA 논문 링크 : https://arxiv.org/abs/2305.14314
'2. 인공지능 논문리뷰 > NLP' 카테고리의 다른 글
| ReACT 논문리뷰 (2) | 2024.11.19 |
|---|