안녕하세요,
오늘은 대학원 입학 전에 참여하였던 Deep daiv에서 다루었던 논문인 ReACT에 대해 리뷰해보도록 하겠습니다.
REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
ReACT
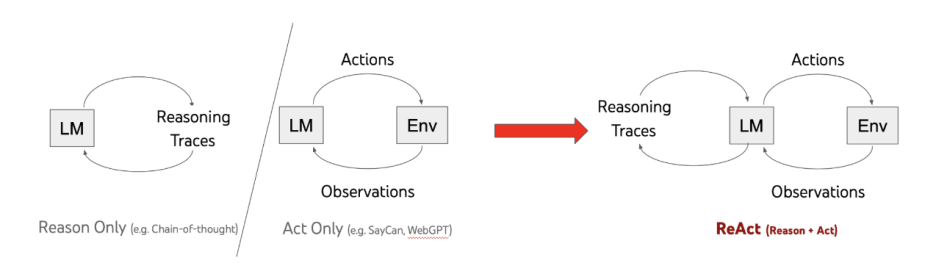
언어모델은 추론과 실행에서 좋아지고 있지만, 두가지 방향은 여전히 분리되어 있다.
ReACT는 두가지 기본 기능을 결합하면 어떻게 되는지를 보여준다.
Abstract
LLM은 언어를 이해하고 대화형 의사결정 작업 전반에 걸쳐 좋은 기능을 보여주었지만 추론 및 실행은 주로 별도의 주제로 연구되었다. 본 문서에서는 추론 추적과 작업별 작업을 interleaved 방식으로 생성하기 위해 LLM을 사용하여 둘 사이의 큰 시너지 효과를 허용하는 방법을 살펴본다.
- Interleaved : 주어진 전파 채널에서, 인접 채널 사이에 추가 채널을 끼워 넣는 것
추론 추적은 모델이 작업 계획을 유도, 추적 및 업데이트하고 처리하는데 도움이 된다.
ReACT 접근 방식을 다양한 언어 및 의사 결정 작업에 적용하고 최첨단 기준에 대한 효율성을 입증할 뿐만 아니라 추론이나 행동 구성 요소가 없는 방법에 대한 향상된 인간 해석성과 신뢰성을 보여준다.
구체적으로 질문 답변(HotpotQA)과 사실 검증(Fever)에서 ReAct는 간단한 Wikipedia API와 상호 작용하여 사고 연쇄 추론에서 널리 퍼져 있는 환각 및 오류 전파 문제를 극복하고 인간과 유사한 작업 해결 궤적을 생성한다. 추론 추적이 없는 기준선보다 더 해석하기 쉽습니다. 두 가지 대화형 의사결정 벤치마크(ALFWorld 및 WebShop)에서 ReAct는 모방 학습 방법과 강화 학습 방법을 각각 34% 및 10%의 절대 성공률로 능가하는 동시에 하나 또는 두 개의 상황 내 예제만 제시한다.
1 INTRODUCTION
인간 지능의 독특한 특징은 과제 지향적인 행동과 언어적 추론을 매끄럽게 결합하는 능력인데, 이 능력은 자기 조절이나 전략화를 가능하게 하고(Vygotsky, 1987; 루리아, 1965; Fernyhough, 2010), 작동 기억을 유지하는 데 인간의 인지에 중요한 역할을 하는 것으로 이론화되었다.(Vygotsky, 1987; 루리아, 1965; Fernyhough, 1992). 부엌에서 접시를 요리하는 예를 생각해 보자. 두 가지 특정 행동 사이에서 우리는 언어로 추론하여 진행 상황을 추적하고("이제 모든 것이 끊겼으니 물솥을 데워야겠어요"), 예외를 처리하거나 상황에 따라 계획을 조정할 수 있다("저는 소금이 없으니 대신 간장과 후추를 사용하게 해주세요"), 외부 정보가 필요할 때를 깨달을 수 있다("제가 반죽을 어떻게 준비하나요? 인터넷으로 검색해볼게요"). 우리는 또한 추론을 지원하고 질문에 답하기 위해(요리책을 열어 레시피를 읽고, 냉장고를 열고, 재료를 확인하는) 행동을 할 수도 있다("지금 당장 어떤 요리를 만들 수 있을까요?"). "연기"와 "추리" 사이의 이러한 긴밀한 시너지 효과는 인간이 새로운 과제를 빠르게 학습하고, 이전에는 볼 수 없었던 상황이나 정보 불확실성에 직면했을 때조차도 강력한 의사 결정이나 추론을 수행할 수 있게 해준다.

최근 결과는 자율 시스템에서 언어적 추론과 상호 작용적 의사 결정을 결합할 수 있는 가능성을 암시했다. 한편, 적절하게 동기 부여된 대규모 언어 모델(LLM)은 산술, 상식 및 상징적 추론 작업의 질문에서 답을 얻기 위해 여러 단계의 추론 트레이스를 수행하는 새로운 기능을 입증했다(Wei et al., 2022). 그러나 이러한 "생각의 사슬" 추론은 모델이 자체 내부 표현을 사용하여 생각을 생성하고 외부 세계에 기반하지 않아 이성적으로 반응하거나 지식을 업데이트하는 능력이 제한된다는 점에서 정적 블랙박스이다. 이는 추론 과정에 대한 사실 환각 및 오류 전파와 같은 문제로 이어질 수 있다(그림 1(1b)). 반면, 최근 연구는 언어 사전을 통한 행동 예측에 초점을 두고 상호 작용 환경에서 계획 및 행동을 위한 사전 훈련된 언어 모델의 사용을 탐구했다.
이러한 접근 방식은 일반적으로 다중 모드 관찰을 텍스트로 변환하고 언어 모델을 사용하여 도메인별 행동 또는 계획을 생성한 다음 컨트롤러를 사용하여 선택하거나 실행한다. 그러나 현재 상태에 대한 공간적 사실을 반복하기 위해 제한된 형태의 언어 추론을 수행하는 Huang et al.(2022b)을 제외하고는 높은 수준의 목표에 대해 추상적으로 추론하거나 연기를 지원하기 위한 작업 메모리를 유지하기 위해 언어 모델을 사용하지 않는다. 몇 개의 블록과 상호 작용하는 이러한 단순한 구현된 작업을 넘어 일반적인 작업 해결을 위해 추론과 연기를 어떻게 시너지 방식으로 결합할 수 있는지, 이러한 조합이 추론 또는 연기 단독에 비해 체계적인 이점을 가져올 수 있는지에 대한 연구는 없었다.
- 쉽게 설명하자면 빨간색 부분은 이유 중심 기준(즉, Reason only)은 지식을 얻고 업데이트하기 위해 외부 환경에 기반을 두지 않고 제한된 내부 지식에 의존해야 하기 때문에 잘못된 정보(빨간색)로 인해 어려움을 겪는다. 행위 전용 기준선(Act only)은 추론이 부족하여 이 경우 ReAct와 동일한 조치 및 관찰을 가짐에도 불구하고 최종 답변을 종합할 수 없다. 이와 대조적으로 ReAct는 해석 가능하고 사실에 기반한 궤적으로 작업을 해결한다.
본 연구에서는 다양한 언어 추론 및 의사 결정 과제를 해결하기 위해 언어 모델과 추론 및 행동을 결합하는 일반적인 패러다임인 ReAct를 제시한다(그림 1). ReAct는 LLM이 인터리브 방식으로 언어적 추론 트레이스와 작업과 관련된 액션을 모두 생성하도록 유도한다. 이를 통해 모델은 동적 추론을 수행하여 연기(연기 이유)에 대한 높은 수준의 계획을 생성, 유지 및 조정하는 동시에 외부 환경(예: 위키피디아)과 상호 작용하여 추론(연기 이유)에 추가 정보를 통합할 수 있다.
질문 답변, 사실 확인, 텍스트 기반 게임 및 웹 페이지 탐색의 네 가지 다양한 벤치마크에 대해 ReAct와 최첨단 기준선에 대한 경험적 평가를 수행한다. 모델이 상호 작용할 수 있는 위키피디아 API에 액세스할 수 있는 HotPotQA와 Fever의 경우, ReAct는 사고 체인 추론(CoT)과 경쟁하면서 바닐라 액션 생성 모델을 능가한다. 전반적으로 가장 좋은 접근 방식은 추론 중 내부 지식과 외부에서 얻은 정보를 모두 사용할 수 있는 ReAct와 CoT의 조합이다. ALFWorld와 WebShop에서 ReAct 프롬프트는 103~105개의 작업 인스턴스로 훈련된 모방 또는 강화 학습 방법을 능가할 수 있으며 성공률이 각각 34%와 10%로 절대적으로 향상되었다. 또한 동작만으로 제어된 기준선에 비해 일관된 이점을 보여줌으로써 의사 결정에서 희소하고 다재다능한 추론의 중요성을 입증한다. 일반적인 적용 가능성과 성능 향상 외에도 인간은 모델의 내부 지식과 외부 환경을 통해 정보를 쉽게 구별할 수 있을 뿐만 아니라 모든 도메인에서 모델 해석성, 신뢰성 및 진단 가능성에 기여한다.
요약하면, (1) 일반적인 작업 해결을 위한 언어 모델에서 추론과 행동을 시너지 효과를 내기 위한 새로운 프롬프트 기반 패러다임인 ReAct를 소개한다. (2) 추론 또는 행동 생성을 개별적으로 수행하는 이전 접근 방식에 비해 몇 번의 샷 학습 설정에서 ReAct의 이점을 보여주기 위해 다양한 벤치마크에 걸쳐 광범위한 실험을 수행한다. (3) 추론 작업에서 행동과 대화형 작업에서 추론의 중요성을 이해하기 위한 체계적인 절제 및 분석을 제시하고, (4)프롬프트 설정에서 ReAct의 한계(즉, 추론 및 행동 지원의 제한)를 분석하고, 추가 훈련 데이터로 개선할 ReAct의 잠재력을 보여주는 초기 미세 조정 실험을 수행한다.
2 REACT: SYNERGIZING REASONING + ACTING
작업 해결을 위해 환경과 상호 작용하는 에이전트의 일반적인 설정을 고려한다. 시간 t 단계에서 에이전트는 환경으로부터 관찰 ot ∈ O를 수신하고 일부 정책 π(at|ct)에 따라 ∈ A에서 작업을 수행하며, 여기서 ct = (o1, a1, · · ·, ot-1, at-1, ot)는 에이전트의 컨텍스트이다. 매핑 ct→ at가 매우 암시적이고 광범위한 계산이 필요한 경우 정책을 학습하는 것이 어렵다. 예를 들어, 그림 1(1c)에 표시된 에이전트는 궤적 컨텍스트(질문, 행동 1-3, 관찰 1-3)에 대한 복잡한 추론이 필요하기 때문에 QA 작업을 완료하기 위한 올바른 최종 작업(행동 4)을 생성할 수 없다. 마찬가지로, 그림 1(2a)에 표시된 에이전트는 싱크베이스 1에 페퍼하이커 1이 포함되어 있지 않아 환각 액션을 계속 생성한다는 컨텍스트를 이해하지 못한다.
ReAct의 아이디어는 간단하다. 에이전트의 행동 공간을 A ˆ = A ∪ L로 확장한다. 생각이나 추론 흔적이라고 할 언어 공간의 행동 a ˆ L은 외부 환경에 영향을 미치지 않으므로 관찰 피드백이 이루어지지 않는다. 대신 생각 ˆt는 현재 상황 ct를 추론하여 유용한 정보를 구성하고 상황 ct+1 = (ct, ˆt)을 업데이트하여 미래의 추론이나 행동을 지원하는 것을 목표로 한다. 그림 1과 같이 다양한 유형의 유용한 생각이 있을 수 있다. 예를 들어 과제 목표를 분해하고 행동 계획을 작성(2b, 1막; 1d, 생각이 1), 과제 해결과 관련된 상식적 지식 주입(2b, 1막), 관찰에서 중요한 부분 추출(1d, 생각이 2, 4), 추적 진행 및 통과 행동 계획(2b, 8막), 예외 처리 및 행동 계획 조정(1d, 생각이 3) 등
그러나 언어 공간 L이 무제한이므로 이 증강 액션 공간에서 학습하는 것은 어렵고 강력한 언어 우선 순위가 필요하다. 본 논문에서는 주로 동결된 대형 언어 모델인 PaLM-540B(Chowdhery et al., 2022)1이 퓨샷 인 컨텍스트 예제로 프롬프트되어 도메인별 액션과 과제 해결을 위한 자유 형식 언어 생각을 모두 생성하는 설정에 초점을 맞춘다(그림 1(1d), (2b)). 각 컨텍스트 예제는 작업 인스턴스를 해결하기 위한 행동, 생각 및 환경 관찰의 인간 궤적이다(부록 C 참조). 추론이 가장 중요한 작업(그림 1(1))의 경우, 저희는 생각과 행동의 생성을 교대로 수행하여 작업 해결 궤적이 여러 생각-행동-관찰 단계로 구성되도록 한다. 대조적으로, 잠재적으로 많은 수의 행동이 수반되는 의사 결정 작업(그림 1(2))의 경우, 생각은 궤적의 가장 관련된 위치에만 드문드문 나타나기만 하면 되므로 언어 모델이 생각과 행동의 비동기적 발생을 스스로 결정하도록 한다.
의사 결정 및 추론 기능이 대규모 언어 모델에 통합되어 있기 때문에 ReAct는 몇 가지 고유한 기능을 누릴 수 있다:
A) Intuitive and easy to design ReAct 프롬프트를 설계하는 것은 인간 주석자가 수행한 작업 위에 언어로 생각을 입력하기 때문에 간단하다. 이 논문에서는 임시 형식 선택, 사고 설계 또는 예제 선택을 사용하지 않는다.
B) General and flexible 유연한 사고 공간과 사고-행동 발생 형식으로 인해 ReAct는 QA, 사실 확인, 텍스트 게임 및 웹 탐색에 국한되지 않는 뚜렷한 행동 공간과 추론 요구를 가진 다양한 작업에 사용할 수 있다.
C) Performant and robust ReAct는 하나의 컨텍스트 내 예제에서만 학습하는 동안 새로운 작업 인스턴스에 대한 강력한 일반화를 보여주며 다양한 도메인에서 추론 또는 행동만으로 일관적으로 기준선을 능가한다. 또한 미세 조정이 활성화된 경우의 추가 이점과 ReAct 성능이 선택을 촉구하는 방법에 대해 보여준다.
D) Human aligned and controllable ReAct는 인간이 쉽게 추론과 사실적 정확성을 검사할 수 있는 해석 가능한 순차적 의사 결정 및 추론 프로세스를 약속한다. 또한 인간은 이동 중인 에이전트 동작을 제어하거나 수정할 수도 있다.
3 KNOWLEDGE-INTENSIVE REASONING TASKS
3.1 SETUP
Domains 지식 검색과 추론에 도전하는 두 가지 데이터 세트를 고려한다: **(1) Hot-PotQA(양 외, 2018)**는 두 개 이상의 위키피디아 구절에 대한 추론이 필요한 멀티홉 질문 답변 벤치마크와 **(2) FEVER(손 외, 2018)**는 주장을 확인할 수 있는 위키피디아 구절이 있는지에 따라 지원, 반박 또는 충분하지 않은 정보를 지원한다. 이 작업에서 저희는 두 작업 모두를 위한 질문 전용 설정에서 운영되며, 모델은 지원 단락에 액세스하지 않고 질문/주장을 입력으로만 받고 추론을 지원하기 위해 외부 환경과의 상호 작용을 통해 내부 지식에 의존하거나 지식을 검색해야 한다.
Action Space 저희는 대화형 정보 검색을 지원하기 위해 세 가지 유형의 액션을 갖춘 간단한 위키피디아 웹 API를 설계한다: (1) search[entity] 해당 엔티티 위키 페이지의 첫 5개 문장을 반환하거나, 아니면 위키피디아 검색 엔진에서 상위 5개 유사 엔티티를 제안하거나, (2) lookup[string] 문자열이 포함된 페이지의 다음 문장을 반환하여 브라우저에서 Ctrl+F 기능을 시뮬레이션한다. (3) finish[answer] 현재 작업을 답변으로 완료한다. 이 액션 스페이스가 대부분 정확한 경로 이름을 기반으로 한 경로의 작은 부분만 검색할 수 있으며, 이는 최첨단 어휘 또는 신경 검색기보다 훨씬 약하다. 목적은 인간이 위키피디아와 어떻게 상호 작용하는지 시뮬레이션하고, 모델이 언어의 명시적인 추론을 통해 검색하도록 하는 것이다.
3.2 METHODS
ReAct Prompting HotpotQA와 Fever의 경우, 훈련 세트에서 무작위로 6개와 3개의 사례2를 선택하고 프롬프트에서 몇 번의 촬영 예제로 사용할 ReAct 형식의 궤적을 수동으로 구성한다. 각 궤적은 여러 생각-행동-관찰 단계(즉, 밀집된 생각)로 구성되어 있으며, 여기서 자유로운 형식의 생각이 다양한 목적으로 사용된다.
Baselines ReAct 궤적을 체계적으로 제거하여 여러 기준선(그림 1(1a-1c)와 같은 형식으로)에 대한 프롬프트를 구축한다. (a) ReAct 궤적에서 모든 생각, 행동, 관찰을 제거하는 표준 프롬프트(표준). (b) 행동과 관찰을 제거하고 추론 전용 기준선 역할을 하는 생각 사슬 프롬프트(CoT)(Wei et al., 2022). 또한 추론 중 디코딩 온도가 0.7인 21개의 CoT 궤적을 샘플링하고 다수 답변을 채택하여 자체 일관성 기준선(CoT-SC)(Wang et al., 2022a;b)을 구축하여 CoT보다 성능을 지속적으로 향상시키는 것으로 나타났다. (c) ReAct 궤적에서 생각을 제거하는 행동 전용 프롬프트(Act)는 WebGPT(Nakano et al., 2021)가 인터넷과 상호 작용하여 질문에 답하는 방식과 거의 유사하지만, 다른 작업과 행동 공간에서 작동하고 프롬프트 대신 모방 및 강화 학습을 사용한다.
Combining Internal and External Knowledge ReAct에서 입증된 문제 해결 과정이 더 사실적이고 근거가 있는 반면 CoT는 추론 구조를 공식화하는 데 더 정확하지만 환각된 사실이나 생각으로 쉽게 고통받을 수 있음을 관찰했다. 따라서 ReAct와 CoT-SC를 통합하고 모델이 다음 휴리스틱을 기반으로 다른 방법으로 전환할 시기를 결정할 것을 제안한다.
A) ReAct → CoT-SC: ReAct가 주어진 단계 내에 답변을 반환하지 못할 때 CoT-SC로 물러난다. 더 많은 단계가 ReAct 성능을 향상시키지 못한다는 것을 알게 됨에 따라 HotpotQA와 FEVER에 대해 각각 7단계와 5단계를 설정했다.
B) CoT-SC → ReAct: n개의 CoT-SC 샘플 중 대다수의 답변이 n/2회 미만으로 발생할 때(즉, 내부 지식이 작업을 자신 있게 지원하지 않을 수 있음) ReAct로 물러난다.
Finetuning 스케일에서 추론 트레이스와 동작에 수동으로 주석을 달아야 하는 어려움으로 인해, ReAct(다른 기준선의 경우에도)에 의해 생성된 정답이 있는 3,000개의 궤적을 사용하여 입력 질문/주장에 따라 조건화된 더 작은 언어 모델(모든 생각, 행동, 관찰)을 디코딩하는 Finetuning(PaLM-8/62B)을 사용하여 Zelikman과 유사한 부트스트래핑 접근 방식을 고려한다.
3.3 RESULTS AND OBSERVATIONS
ReAct outperforms Act consistently
ReAct는 모두에서 Act보다 우수하며, 특히 최종 정답을 종합하기 위해 연기를 지도하는 추론의 가치를 보여준다.

ReAct vs. CoT
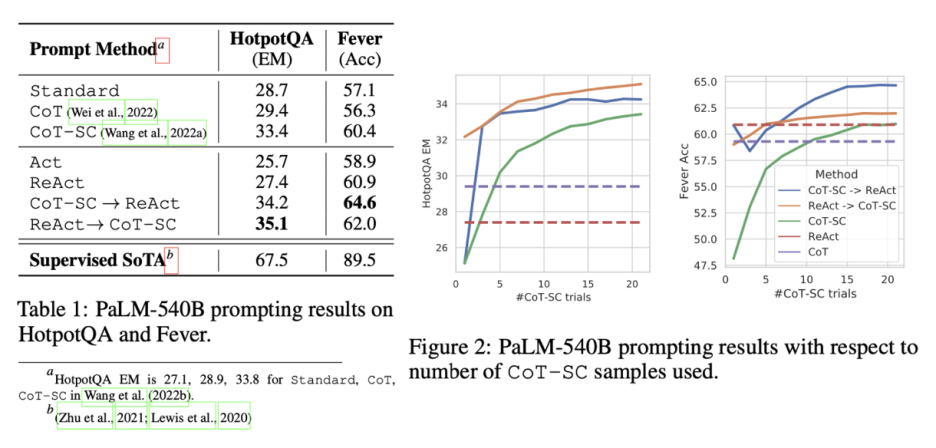
반면 ReAct는 Fever의 CoT(60.9 대 56.3)를 능가하고 HotpotQA의 CoT(27.4 대 29.4)에 약간 뒤떨어져 있다. SUPS/REFUTES에 대한 Fever 클레임은 약간만 다를 수 있으므로 정확하고 최신 지식을 얻기 위해 행동하는 것이 중요하다. HotpotQA에서 ReAct와 CoT의 행동 차이를 더 잘 이해하기 위해 ReAct와 CoT에서 각각 정답과 오답(EM으로 판단)으로 50개의 궤적을 무작위로 샘플링하고(총 200개의 예제), 표 2에서 성공 모드와 실패 모드에 수동으로 레이블을 지정했다. 몇 가지 주요 관찰 사항은 다음과 같다 A) Hallucination(환각) is a serious problem for CoT. B) 추론, 행동 및 관찰 단계를 인터리빙하면 ReAct의 근거성과 신뢰성이 향상되지만, 이러한 구조적 제약은 추론 단계를 공식화하는 데 있어 유연성을 감소시키기도 한다. C) ReAct의 경우 검색을 통해 정보 지식을 성공적으로 검색하는 것이 중요하다.
ReAct + CoT-SC perform best for prompting LLMs T
able1에서 볼 수 있듯이 HotpotQA와 Fever에 대한 가장 좋은 프롬프트 방법은 각각 ReAct → CoT-SC 및 CoT-SC → ReAct다. 또한 Figure 2는 사용된 CoT-SC 샘플 수와 관련하여 서로 다른 방법이 어떻게 수행되는지 보여준다. 두 가지 ReAct + CoT-SC 방법은 각각 하나의 작업에서 유리하지만 서로 다른 샘플 수에서 CoT-SC보다 상당히 그리고 지속적으로 우수하여 3-5개의 샘플만 사용하여 21개의 샘플로 CoT-SC 성능에 도달했다. 이러한 결과는 추론 작업을 위해 모델 내부 지식과 외부 지식을 적절하게 결합하는 가치를 나타낸다.
ReAct performs best for fine-tuning
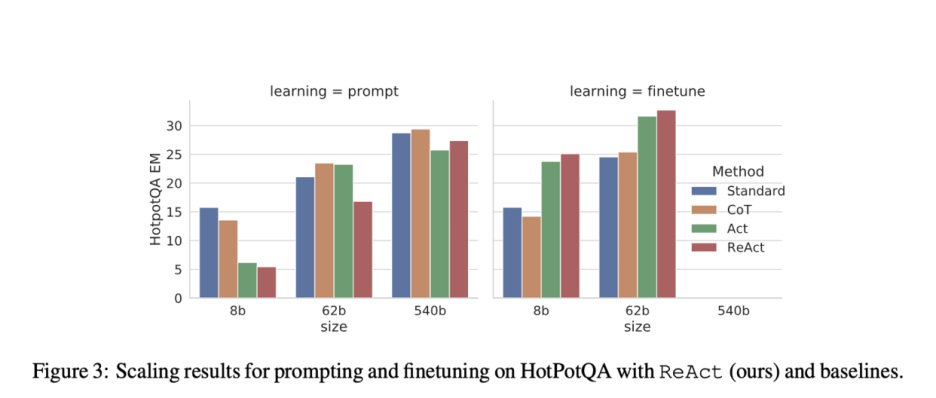
Figure 3은 HotpotQA에서 네 가지 방법(Standard, CoT, Act, ReAct)을 프롬프트/파인튜닝하는 것의 스케일링 효과를 보여준다. PaLM-8/62B에서는 상황 내 예제에서 추론과 행동을 모두 배우기 어렵기 때문에 프롬프트 ReAct가 네 가지 방법 중 가장 좋지 않은 성능을 발휘한다. 그러나 단 3,000개의 예제로 미세 조정할 때 ReAct는 네 가지 방법 중 가장 좋은 방법이 되는데, PaLM-8B 미세 조정 ReAct가 모든 PaLM-62B 프롬프트 방법을 능가하고 PaLM-62B 미세 조정 ReAct가 모든 540B 프롬프트 방법을 능가한다. 대조적으로, 전자는 모델에게 (잠재적으로 내재된) 지식 사실을 기억하는 방법을 가르치고, 후자는 모델에게 지식 추론에 대한 보다 일반화 가능한 기술인 위키피디아에서 정보에 액세스하는 방법(이유 및 행동)을 가르치기 때문에 파인튜닝 Standard 또는 CoT는 두 PaLM-8/62B 모두에 대해 파인튜닝 ReAct 또는 Act보다 훨씬 더 좋지 않다. 모든 프롬프트 방법은 여전히 도메인별 최첨단 접근 방식과 상당히 거리가 있기 때문에(Table1), 더 많은 사람이 작성한 데이터로 파인튜닝하는 것이 ReAct의 힘을 발휘하는 더 나은 방법이 될 수 있다고 생각한다.
- 정리하자면, finetunning 하기 전에는 ReACT 성능이 가장 좋지 않지만, Finetunning을 한 경우에는 ReACT의 성능이 가장 좋다.
4 DECISION MAKING TASKS
ALFWorld와 WebShop의 두 가지 언어 기반 대화형 의사 결정 과제에 대해 ReAct Test
ALFWorld
ALFWorld(Shridhar et al., 2020b)(Figure 1(2))는 구체화된 ALFED 벤치마크(Shridhar et al., 2020a)에 맞게 설계된 합성 텍스트 기반 게임. 여기에는 에이전트가 텍스트 동작을 통해 시뮬레이션된 가정을 탐색하고 상호 작용하여 높은 수준의 목표를 달성해야 하는 6가지 유형의 작업이 포함된다. 작업 인스턴스에는 50개 이상의 위치가 있을 수 있고 전문가 정책이 50단계 이상 소요될 수 있으므로 에이전트가 하위 목표를 계획하고 추적하는 것은 물론 체계적으로 탐색하도록 합니다. 특히 ALFWorld에 구축된 한 가지 과제는 일반적인 가정 용품의 가능한 위치를 결정해야 한다는 것이며, 이 환경을 LLM이 사전 교육된 상식을 활용하기에 적합하게 만든다. React를 촉구하기 위해 각 작업 유형에 대한 훈련 세트에서 세 가지 궤적에 무작위로 주석을 달는데, 각 궤적에는 (1) 목표를 분해하고, (2) 목표를 추적하고, (3) 다음 하위 목표를 결정하고, (4) 대상을 어디서 찾을 것인지, 무엇을 해야 하는지에 대한 상식을 통한 이유가 포함된다.
WebShop
React는 실제 응용 프로그램을 위해 시끄러운 실제 언어 환경에서도 상호 작용할 수 있는지 확인하였다.
Results
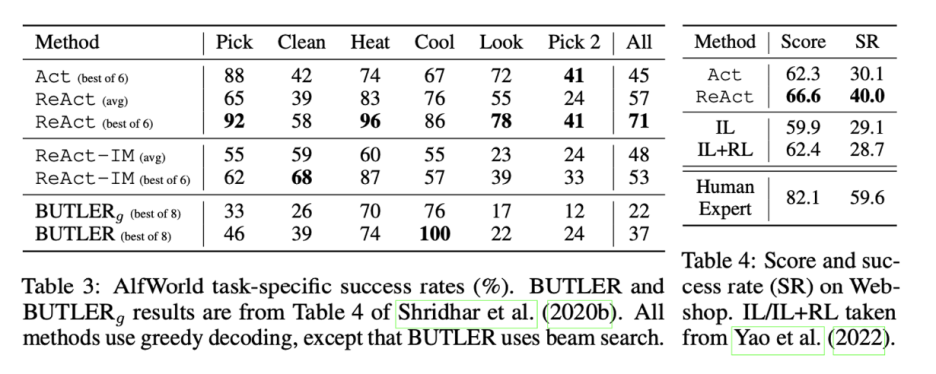
ReAct는 ALFWorld(Table 3)와 Webshop(Table 4) 모두에서 Act를 능가한다. ALFWorld에서 최고의 ReAct 평가판은 평균 71%의 성공률을 달성하여 최고의 Act(45%) BULLTER(37%) 평가판을 크게 능가한다. 실제로 더 나쁜 ReAct 평가판(48%)도 두 가지 방법 모두에서 최고의 평가판을 능가한다. 더욱이 Act에 비해 ReAct의 이점은 6개의 통제된 시행에서 일관되며 상대적인 성능 향상은 33%에서 90% 범위에 이르고 평균 62%이다.
Webshop에서 one-shot Act prompting은 이미 IL 및 IL+RL 방법과 동등한 성능을 발휘한다. 추가 희소 추론을 통해 ReAct는 이전 최고의 성공률보다 절대적으로 10% 향상된 훨씬 더 나은 성능을 달성한다. 예제를 확인함으로써 ReAct가 시끄러운 관찰과 행동 사이의 격차를 줄이기 위해 추론을 통해 명령 관련 제품과 옵션을 식별할 가능성이 더 높다는 것을 발견했습니다(예: "거실을 위한 공간 절약 오스만 벤치"의 경우 '39x18x18인치' 및 '파란색' 옵션이 있으며 구매하기에 좋은 것 같습니다."). 그러나 기존 방법은 프롬프트 기반 방법에 대해 여전히 어려운 훨씬 더 많은 제품 탐색 및 쿼리 재구성을 수행하는 전문가의 성능과는 여전히 거리가 있다(Table 4).
5 RELATED WORK
Language model for reasoning
추론에 LLM을 사용하는 가장 잘 알려진 작업은 아마도 Chain-of-Thought (CoT)일 것이다. 그 이후 복잡한 작업을 가장 적게 해결하도록 유도하는 작업(Zhou et al., 2022), zero-shot- CoT, reasoning with self-consistency 등 여러 후속 작업이 수행되었다. 최근 (Madan & Yazdanbaksh, 2022)은 CoT의 공식화와 구조를 체계적으로 연구했으며 상징, 패턴 및 텍스트의 존재가 CoT의 효과에 중요하다는 것을 관찰했다. 다른 작업도 단순한 유도를 넘어 보다 정교한 추론 아키텍처로 확장되었다. React는 단순히 고립되고 고정된 추론 이상을 수행하고 모델 행동과 해당 관찰을 일관된 입력 스트림으로 통합하여 추론을 넘어 작업을 보다 정확하게 추론하고 해결한다(예: interactive decision making).
Language model for decision making
LLM의 강력한 기능으로 언어 생성을 넘어 작업을 수행할 수 있게 되었으며 특히 대화형 환경에서 의사 결정을 위한 정책 모델로 LLM을 활용하는 것이 점점 대중화되고 있다. WebGPT는 LM을 사용하여 웹 브라우저와 상호 작용하고 웹 페이지를 탐색하며 ELI5에서 복잡한 질문에 대한 답변을 추론한다. React와 비교하여 WebGPT는 사고 및 추론 절차를 명시적으로 모델링하지 않고 강화 학습을 위해 값비싼 인간 피드백에 의존한다. 대화 모델링에서 BlenderBot 및 Sparrow와 같은 챗봇과 SimpleTOD 와 같은 작업 중심 대화 시스템도 LM이 API 호출에 대한 의사 결정을 내리도록 훈련시킨다. React와 달리 추론 절차도 명시적으로 고려하지 않으며 정책 학습을 위해 값비싼 데이터 세트와 인간 피드백 수집에 의존한다. 이와 달리 React는 의사 결정 과정에서 추론 절차의 언어 설명만 필요하기 때문에 훨씬 저렴한 방법으로 정책을 학습한다.
6 CONCLUSION
ReAct는 대규모 언어 모델에서 추론과 행동을 시너지 효과적으로 수행하기 위한 간단하지만 효과적인 방법이다. multi-hop question-answering에서, 사실 확인 및 상호 의사 결정 작업에 대한 다양한 실험을 통해 ReAct가 해석 가능한 의사 결정 추적을 통해 우수한 성능으로 이어진다는 것을 보여준다. ReACT는 단순성에도 불구하고, 대규모 작업 공간이 있는 복잡한 작업은 잘 학습하기 위해 더 많은 시연이 필요하며, 안타깝게도 context 내 학습의 입력 길이 제한을 쉽게 넘어설 수 있다. HotpotQA에 대한 미세 조정 접근 방식을 탐구하지만, 보다 고품질의 인간 주석을 통해 학습하는 것이 성능을 더욱 향상시키는 데 필요한 요소가 될 것이다. multi-task training으로 ReAct를 확장하고 강화 학습과 같은 보완적인 패러다임과 결합하면 더 많은 응용 프로그램에 대한 LLM의 잠재력을 더욱 높이는 더 강력한 에이전트가 될 수 있다.
'2. 인공지능 논문리뷰 > NLP' 카테고리의 다른 글
| QLoRA(Quantized Low-Rank Adapter) 논문 간단리뷰 (1) | 2024.11.27 |
|---|