Abstract
대형 언어 모델(LLM)은 다양한 작업과 상황에서 유용하게 활용되고 있지만, 이를 신뢰할 수 있는 방식으로 평가하는 방법을 개발하는 것은 여전히 어려운 과제이다. 현대의 평가 방법들은 종종 LLM을 이용하여 다른 LLM이 생성한 응답을 평가하는 방식에 의존한다. 그러나, LLM을 평가자로 활용하는 방식의 효과성을 평가하기 위한 메타 평가(meta-evaluation)는 기존 벤치마크의 한정된 범위에 의존하거나, 광범위한 인간 주석이 필요하다는 문제를 안고 있다. 이러한 한계를 극복하기 위해, 우리는 다양한 작업과 사용자 정의된 새로운 시나리오에서도 LLM의 평가 성능을 효과적이고 신뢰할 수 있으며 효율적으로 평가할 수 있는 확장 가능한 메타 평가 방법이 시급히 필요함을 강조한다.
이를 해결하기 위해, 우리는 SCALEEVAL이라는 다중 LLM 에이전트의 상호 토론을 활용한 메타 평가 프레임워크를 제안한다. 이 프레임워크는 다중 라운드 토론을 통해 인간 주석자들이 가장 신뢰할 수 있는 LLM 평가자를 판별하는 데 도움을 주며, 이를 통해 기존 메타 평가에서 요구되었던 대규모 인간 주석 작업의 부담을 크게 줄일 수 있다. 우리는 이 프레임워크의 코드를 공개하며, 이는 GitHub 링크에서 확인할 수 있다.
요약 : LLM을 평가자로 활용하는 방식의 효과성을 평가하기 위한 메타 평가(meta-evaluation)는 기존 벤치마크의 한정된 범위에 의존하거나, 광범위한 인간 주석이 필요하다는 문제가 있으므로, 다중 LLM 에이전트의 상호 토론을 활용한 메타 평가 프레임워크를 제안한다. 이를 통해 대규모 인간 주석 작업의 부담을 줄일 수 있다.
Introduction
대형 언어 모델(LLM)은 빠르게 발전하여 다양한 작업을 뛰어난 성능으로 수행할 수 있게 되었다(Bubeck et al., 2023; Gemini Team et al., 2023). 이러한 발전은 다양한 흥미로운 응용 가능성을 열어주었지만, 동시에 생성된 출력물을 평가하는 데 있어 복잡한 문제를 초래했다. 현재 LLM 평가 연구는 주로 자동 평가 지표(Fu et al., 2023; Li et al., 2023c; Zheng et al., 2023; Wang et al., 2023a)를 중심으로 이루어지고 있으며, 많은 경우 LLM 자체가 평가자로 활용되고 있다. 그러나 이러한 LLM 평가자들이 새로운 작업에 적용될 때, 과연 신뢰할 수 있는 평가를 수행할 수 있는가 하는 문제가 제기된다. 많은 경우 이에 대한 명확한 답을 얻기 어렵다.

한편, 일부 운이 좋은 과제에서는 평가 지표에 대한 메타 평가(평가 지표의 평가)가 철저하게 수행되기도 했다(§2). 일반적으로 이러한 메타 평가는 특정 기준(예: 출력물의 유창성, 입력에 대한 의미적 충실성)에 대한 인간 주석 데이터를 수집하여 진행된다. 예를 들어, 기계 번역 품질 지표의 경우 WMT metrics task(Freitag et al., 2022)에서 광범위한 메타 평가 데이터가 축적되었으며, 요약 평가에서는 TAC 및 RealSum 데이터셋(Dang et al., 2008; Bhandari et al., 2020)이 존재한다. 이러한 데이터셋이 수집되면, 자동 평가 지표와 인간 평가 데이터 간의 상관관계를 측정하여 메타 평가를 수행할 수 있다(§3).
그러나 이러한 데이터셋을 구축하는 데는 많은 비용이 소요되며, 숙련된 전문가가 세밀한 주석 작업을 수행해야 한다는 점에서 실용적인 한계를 갖는다. 최근 LLM이 수학 문제 해결(Hendrycks et al., 2021), 독해(Zhong et al., 2023), 창작 글쓰기(Zheng et al., 2023), 다국어 응용(Hu et al., 2020; Bang et al., 2023) 등 다양한 용도로 활용되고 있는 만큼, 새로운 작업마다 이러한 인간 주석 기반 평가 데이터를 구축하는 것은 현실적으로 어렵다. 이로 인해, 충분한 검증 없이 LLM이 평가자로 사용되는 사례가 많아지고 있으며, 많은 경우 이러한 LLM 평가자들이 신뢰할 수 없다는 문제점이 제기된다(Wang et al., 2023b; Huang et al., 2023).
본 논문에서는 LLM 시대에 맞는 SCALEEVAL이라는 확장 가능한 메타 평가 프레임워크를 제안한다. 이 프레임워크는 다양한 작업과 시나리오에서 메타 평가 벤치마크를 구축하는 데 중점을 둔다(§4). SCALEEVAL은 다중 LLM 에이전트 간의 토론을 기반으로 하며, LLM 평가자 간 의견이 일치하지 않는 경우 최소한의 인간 개입을 통해 조정이 이루어진다(그림 1). 이 프레임워크는 사용자가 자신만의 프롬프트와 응답을 활용하여 원하는 시나리오와 기준을 설정할 수 있도록 설계되어, 다양한 평가 맥락에서 높은 유연성과 적응성을 제공한다.
본 연구에서는 SCALEEVAL의 메타-메타 평가(§6)를 수행하여, 우리의 접근 방식이 인간 전문가만을 활용한 메타 평가와 높은 상관관계를 가지는지를 입증한다. 또한, 다양한 시나리오에서 LLM 평가자들의 신뢰성과 비용-성능 간의 균형을 평가하고, 그들의 평가자로서의 특정한 역량과 한계를 면밀히 분석한다(§7). 아울러, 평가 과정에서 사용되는 프롬프트 변형이 LLM 평가자의 성능에 미치는 영향을 살펴본다(§8).
우리의 프레임워크는 오픈 소스로 제공되며, 연구 커뮤니티가 자신만의 프롬프트, LLM 응답, 평가 기준 및 시나리오를 활용하여 LLM 평가자를 대상으로 메타 평가를 수행할 수 있도록 지원한다.

요약 : 현재 LLM 평가 연구는 주로 자동 평가 지표를 중심으로 이루어지고 있으며, 많은 경우 LLM 자체가 평가자로 활용되고 있다. 그러나 여기서 몇가지 문제점이 있다.
1) LLM 평가자들이 새로운 작업에 적용될 때, 신뢰할 수 있는 평가를 수행할 수 있는가 하는 문제
2) 데이터셋을 구축하는데 많은 비용이 소요되며, 전문가가 세밀한 주석 작업을 수행해야 하는 문제 (여러가지 task들(수학문제, 독해, 창작 글쓰기 등)마다 인간 주석 기반 평가 데이터를 구축하는 문제점)
따라서, 본 논문에서는 다양한 작업과 시나리오에서 메타 평가 벤치마크를 구축하는 데 중점을 둔다. 다시 말하면 다중 LLM 에이전트 간의 토론을 기반으로 하며, LLM 평가자 간 의견이 일치하지 않는 경우 최소한의 인간 개입을 통해 조정한다. (높은 유연성과 적응성을 제공)
Related Work
2.1 대형 언어 모델(LLM) 출력의 자동 평가 (Automatic Evaluation of LLM Output)
대형 언어 모델(LLM)을 평가하는 가장 일반적인 패러다임은 논리적 추론(예: BigBench (Srivastava et al., 2022)), 상식적 질의응답(예: MMLU (Hendrycks et al., 2020)), 코드 생성(예: HumanEval (Chen et al., 2021b))과 같은 표준 벤치마크를 기반으로 LLM의 성능을 평가하는 것이다. 이러한 벤치마크는 모델의 성능을 측정하는 데 유용하지만, 자유 형식의 텍스트 생성을 요구하는 개방형 작업에서의 모델 능력을 측정하는 데는 한계가 있다.
LLM의 능력이 급격히 향상됨에 따라, LLM 평가 방식도 단순한 벤치마크 성능 평가에서 벗어나 모델이 생성한 텍스트 자체를 평가하는 방식으로 변화하고 있다(Fu et al., 2023; Li et al., 2023c; Zheng et al., 2023; Wang et al., 2023a). 최근에는 다중 에이전트 토론 방식을 활용하여 평가 신뢰도를 높이는 연구도 진행되고 있다(Chan et al., 2023; Li et al., 2023b). 이러한 접근 방식은 LLM의 지시 수행 능력과 다재다능함을 활용할 수 있지만, LLM을 평가자로 직접 활용하는 것은 사용자 정의 시나리오에서 그 정확성을 보장할 수 없다는 한계를 가진다. 우리는 이러한 문제를 해결하기 위해 확장 가능한 메타 평가 방식을 도입하여, 다양한 시나리오에서도 평가의 신뢰성을 보장하고자 한다.
또한, 널리 사용되는 평가 플랫폼인 Chatbot Arena (Zheng et al., 2023)는 다양한 사용자 프롬프트를 수집하는 크라우드소싱 방식을 지원한다. 하지만 이 플랫폼에서 LLM 성능을 평가하는 과정은 인간 평가에 크게 의존하며, 특정 작업이나 시나리오에서 LLM 능력을 평가하려는 모든 사람이 쉽게 접근할 수 있는 것은 아니다. 또한, 인간 평가자들은 표준화된 기준을 따르지 않거나 명확한 평가 지침이 없을 수 있어, 평가 결과가 편향되거나 부정확할 가능성이 있다.
요약 : 대형 언어 모델을 평가하는 일반적인 방식 : 논리적 추론, 상식적 질의응답, 코드 생성. (자유 형식의 텍스트 생성을 요구하는 작업에서의 모델 능력을 측정하는 데는 한계가 존재).
LLM이 빠르게 발전해감에 따라 평가 방식도 단순한 벤치마크가 아닌 모델이 생성한 텍스트 자체를 평가하는 방식으로 변화하고 있다. 다중 에이전트 토론 방식을 활용하여 평가 신뢰도를 높이는 연구도 진행되고 있지만, 정확성을 보장할 수 없다는 한계가 존재함에 따라 확장 가능한 메타 평가 방식을 도입.
2.2 LLM을 평가자로 활용한 메타 평가 (Meta-Evaluation of LLMs as Evaluators)
LLM을 평가자로 활용하는 방법을 제안한 이전 연구들은 주로 다음 세 가지 방식으로 메타 평가를 수행했다.
- 기존 자연어처리(NLP) 메타 평가 벤치마크 활용 (Fu et al., 2023; Chan et al., 2023)
- 특정 작업이나 시나리오에 대해 전문가가 주석한 데이터셋을 이용한 소규모 메타 평가 (Chiang and Lee, 2023; Wang et al., 2023a; Zheng et al., 2023)
- 크라우드소싱 플랫폼을 활용한 인간 주석 데이터 수집 (Zheng et al., 2023)
그러나 기존 데이터셋의 한정된 범위 및 주석 예산의 부족으로 인해, 방식 (1)과 (2)는 본질적으로 포괄성이 떨어지는 한계를 가진다. 반면, 방식 (3)은 크라우드소싱을 통해 더 포괄적인 메타 평가를 수행할 수 있지만, 메타 평가 과정에서 요구되는 대량의 인간 주석 작업이 확장성을 제한하며, 크라우드 워커들이 복잡한 작업을 정확하게 평가하지 못할 가능성도 존재한다.
이러한 문제를 해결하기 위해, 본 연구에서는 다중 에이전트 토론을 활용한 메타 평가 방법을 제안하여 기존 평가 방식의 한계를 극복하고자 한다.
3. 사전 지식 (Preliminaries)
본 섹션에서는 자동 평가 및 메타 평가 시스템의 개념을 소개하며, 특히 생성형 AI 시대의 LLM 출력 평가를 중점적으로 다룬다.
3.1 주요 용어 정의
논문 전반에서 사용될 핵심 용어를 정의하면 다음과 같다.
- 기준 (Criterion): LLM이 생성한 응답의 품질을 평가하는 데 사용되는 기준이다. 예를 들어, 도움이 되는 정도(Helpfulness), 유창성(Fluency), 사실성(Factuality), 창의성(Creativity) 등이 있다.
- 시나리오 (Scenario): 사용자가 LLM과 상호작용하는 실제 환경을 설명한다. 예를 들어, 브레인스토밍(Brainstorming), 코딩(Coding), 대화(Dialog) 등이 있다.
3.2 자동 평가 (Automatic Evaluation)
자동 평가 방법은 주어진 프롬프트와 평가 기준에 따라 LLM이 생성한 응답의 품질을 측정하는 방식이다. 일반적으로 자동 평가는 단일 응답 평가(Single-Response Evaluation) 또는 응답 간 비교(Pairwise Response Comparison) 방식으로 이루어진다(Ouyang et al., 2022; Zheng et al., 2023; Li et al., 2023a). 본 연구에서는 후자의 방식을 집중적으로 다룬다.
응답 간 비교 방식은 인간과 LLM 모두에게 직관적인 평가 방법이며, 모델의 승률(Win Rate)과 Elo 점수를 계산하여 상대적 성능을 쉽게 이해할 수 있도록 한다(Zheng et al., 2023). 이를 수식으로 정의하면 다음과 같다.

여기서,
- E: 자동 평가 모델
- c: 사용자 정의 평가 기준 (예: 도움 정도, 논리적 추론 등)
- p: 사용자 프롬프트
- r1, r2: 두 개의 비교 대상 응답
- o: 평가 결과 (1: r1이 더 우수함, 0: 동등함, -1: r2가 더 우수함)
3.3 메타 평가 (Meta-Evaluation)
메타 평가는 자동 평가 지표의 품질을 측정하는 과정이다. 이를 정식화하면, 메타 평가는 인간 전문가의 평가 결과를 **골드 스탠다드(G)**로 설정하고, 자동 평가 지표(E)와 비교하여 신뢰성을 측정하는 방식으로 이루어진다.
예제 수준 합의율 (Example-Level Agreement Rate)
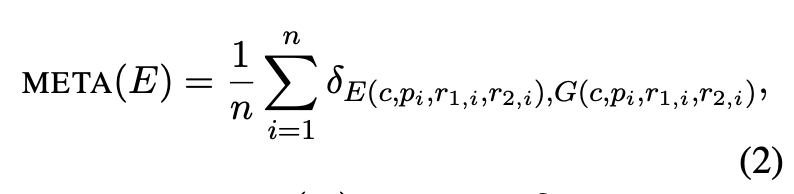
시스템 수준 합의율 (System-Level Agreement Rate)
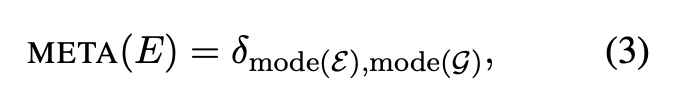
여기서,
- δ: Kronecker 델타 함수
- mode(·): 가장 빈번하게 등장하는 평가 결과
높은 합의율을 보일수록 자동 평가 지표(E)가 인간 전문가의 평가(G)와 높은 일관성을 갖는다는 의미이다.
본 연구에서는 이러한 자동 평가와 메타 평가 개념을 확장하여, 다중 에이전트 토론을 활용한 확장 가능한 메타 평가(SCALEEVAL) 프레임워크를 제안한다. 이 방법은 다양한 시나리오에서 LLM의 평가자로서의 신뢰성을 검증하는 데 기여할 것이다.
Methodology
이 섹션에서는 SCALEEVAL이 메타 평가, 자동 평가, 그리고 인간 전문가에 의한 메타-메타 평가를 수행하는 데 사용하는 프레임워크를 상세히 설명한다.
SCALEEVAL의 메타 평가는 앞서 설명한 응답 간 비교(pairwise response comparison) 설정을 따른다(§3.3). 하지만 기존 방식과 달리, 인간 노동력에 의존하여 메타 평가 벤치마크 G를 구축하는 대신, 확장 가능한 다중 에이전트 토론 기반 프레임워크를 활용하여 G를 구축한다. 평가 과정은 §3.2에서 설명한 응답 간 비교 방식을 따른다. 또한, 메타-메타 평가 과정 역시 메타 평가의 원칙을 적용하며, 이 과정은 다중 에이전트 토론 기반 메타 평가 프레임워크의 신뢰성을 검증하는 역할을 한다.
4.1 다중 에이전트 토론 기반 메타 평가 프레임워크
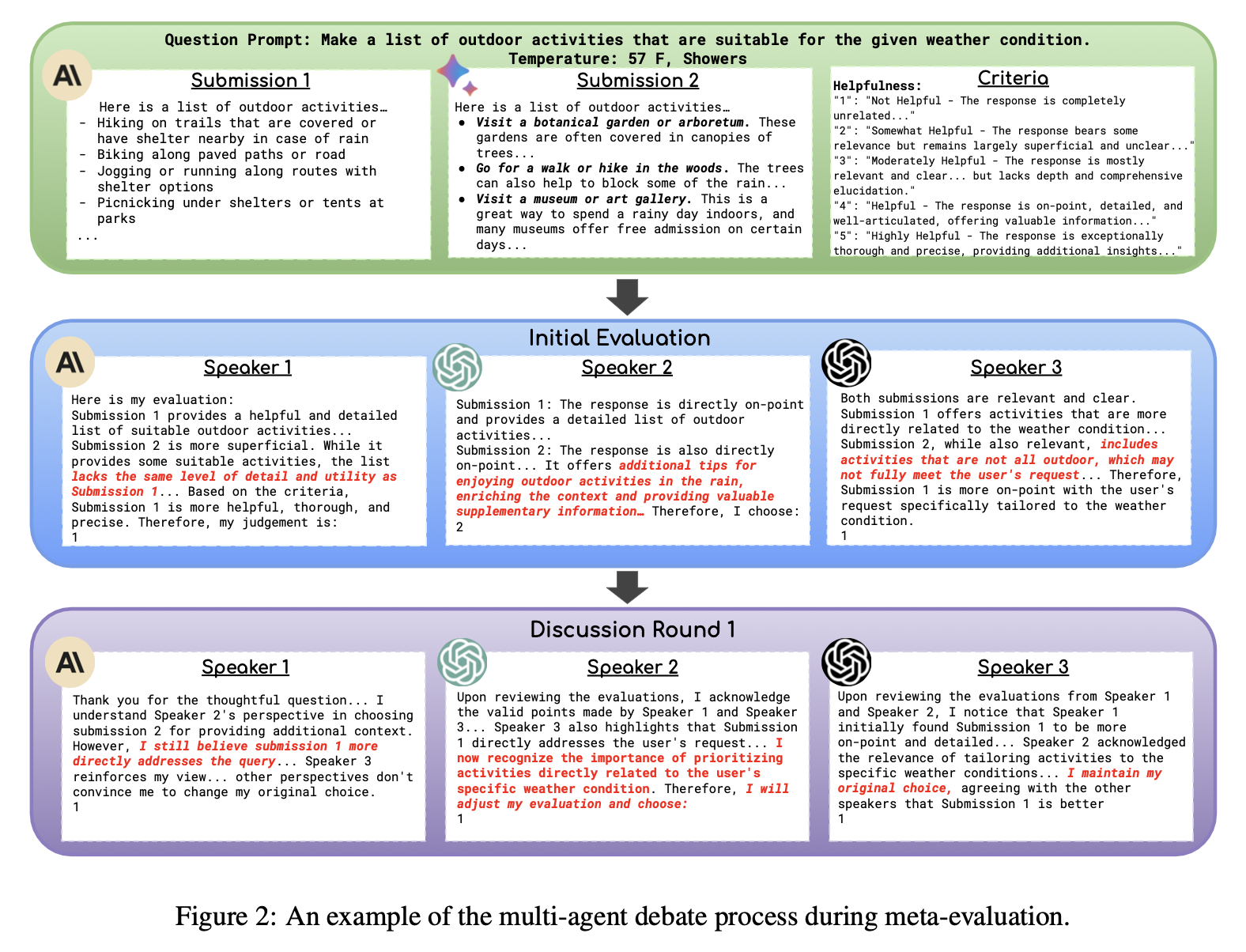
메타 평가 프레임워크는 다수의 LLM 에이전트 Aj 가 여러 라운드에 걸쳐 서로 논의(d = 0 ~ D - 1)를 진행하는 방식으로 설계되었다. 이는 기존 메타 평가 방식과 비교하여 훨씬 적은 시간과 비용이 소요된다. 다중 에이전트 토론 기반 메타 평가 프레임워크를 활용하면, 각 LLM 에이전트가 질의 프롬프트 pi, 두 개의 LLM 응답 r1,i,r2,i, 그리고 평가 기준 c에 대한 이해를 바탕으로 평가를 수행할 수 있다. 각 LLM 에이전트는 응답 중 어느 것이 더 나은지 평가하고, 이에 대한 정당한 이유(Justification)를 제공한다. 또한, 초기 평가 이후 다른 에이전트들의 평가 결과와 논리를 검토한 후, 평가를 수정할 수도 있다.
초기 평가 (첫 번째 논의 라운드, d=0)
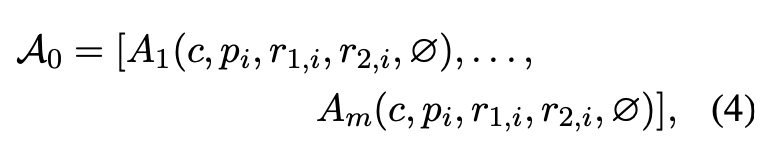
각 LLM 에이전트는 아래와 같은 평가 결과를 제공한다.
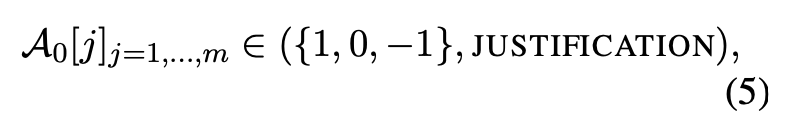
여기서,
- 1: r1,i이 더 나음
- 0: 두 응답이 동등함
- -1: r2,i이 더 나음
후속 논의 라운드 ( d=1∼D−1)
이후 라운드에서는 각 에이전트가 이전 평가 결과 Ad−1을 검토하고, 자신의 평가를 수정할 기회를 갖는다.
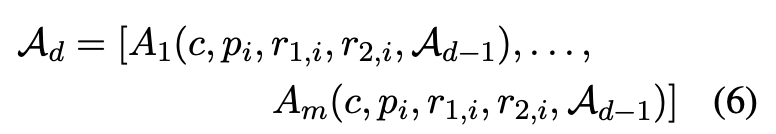
여기서, 각 평가 결과는 여전히
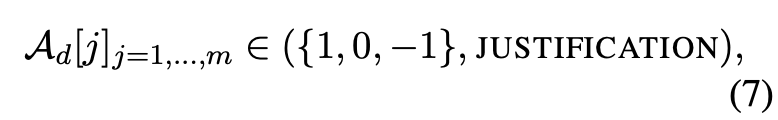
형식을 따른다.
논의가 최종 라운드 d=D−1까지 진행된 후에도 의견이 일치하지 않는다면, 인간 평가자가 개입하여 최종 결정을 내린다. 인간 평가자는 LLM 에이전트들이 제공한 평가 보고서를 검토하여 최종 결론을 내리며, 이를 통해 평가 신뢰도를 높인다. 이 방식은 자동 평가의 확장성과 인간 평가자의 신뢰성 사이에서 균형을 유지하는 역할을 한다.
그림 2는 다중 에이전트 토론 과정의 예시를 보여준다
4.2 자동 평가 프레임워크
본 연구에서는 응답 간 비교(pairwise response comparison) 방식 (§3.2)을 따른다. LLM이 평가자로 사용될 경우, 일반적으로 개별 LLM(Fu et al., 2023; Li et al., 2023c; Zheng et al., 2023; Wang et al., 2023a)을 활용하거나, 다중 에이전트 토론을 활용한 방법(Chan et al., 2023; Li et al., 2023b)이 사용된다. SCALEEVAL에서는 단일 LLM(예: GPT-3.5-turbo)을 평가자로 활용하는 방식을 기본으로 설정하지만, 프레임워크는 다른 평가자 구성에도 적용 가능하다.
4.3 인간 전문가 메타-메타 평가
제안된 메타 평가 프레임워크의 신뢰성을 검증하기 위해, **메타-메타 평가(meta-meta evaluation)**를 수행한다. 메타-메타 평가는 메타 평가 프로세스 (§3.3)와 동일한 방식으로 진행된다.
- 자동 평가 지표 E: 다중 에이전트 토론을 활용한 평가 결과
- 골드 스탠다드 G: 인간 전문가의 평가 결과
이러한 설정을 통해, 다중 에이전트 토론 기반 메타 평가가 인간 전문가의 평가와 어느 정도 일치하는지 검증할 수 있다. 높은 일치율을 보이면, 본 연구에서 제안한 프레임워크가 신뢰할 수 있는 평가 방법임을 입증하는 것이다.
Experiments
본 섹션에서는 SCALEEVAL의 성능을 평가하기 위해 수행한 다양한 실험을 소개한다. 실험은 크게 세 가지로 구성된다.
- 실험 I (Exp-I): 다중 에이전트 토론의 메타-메타 평가
→ SCALEEVAL이 인간 전문가의 평가 결과와 얼마나 일치하는지 검증 - 실험 II (Exp-II): LLM 평가자 vs. 메타 평가
→ LLM을 평가자로 활용할 때, 각 모델이 얼마나 신뢰할 수 있는지 분석 - 실험 III (Exp-III): 평가 기준 프롬프트 변형에 따른 평가 신뢰도
→ 평가 기준 프롬프트의 표현 방식이 LLM 평가자의 평가 결과에 미치는 영향 분석
6. 실험 I: 다중 에이전트 토론의 메타-메타 평가
목적
SCALEEVAL의 메타 평가 결과가 인간 전문가 평가와 얼마나 일치하는지 검증하기 위해 메타-메타 평가를 수행한다.
설정
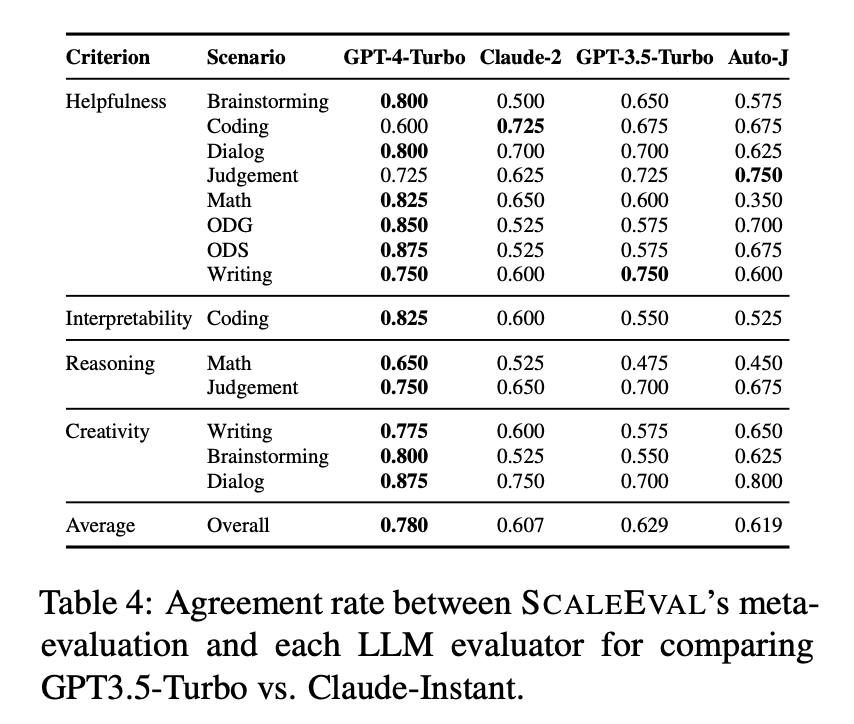
- LLM 에이전트: GPT-4-turbo, Claude-2, GPT-3.5-turbo
- 테스트 프롬프트: 총 160개 (AlpacaEval 137개, HumanEval 10개, GSM-Hard 13개)
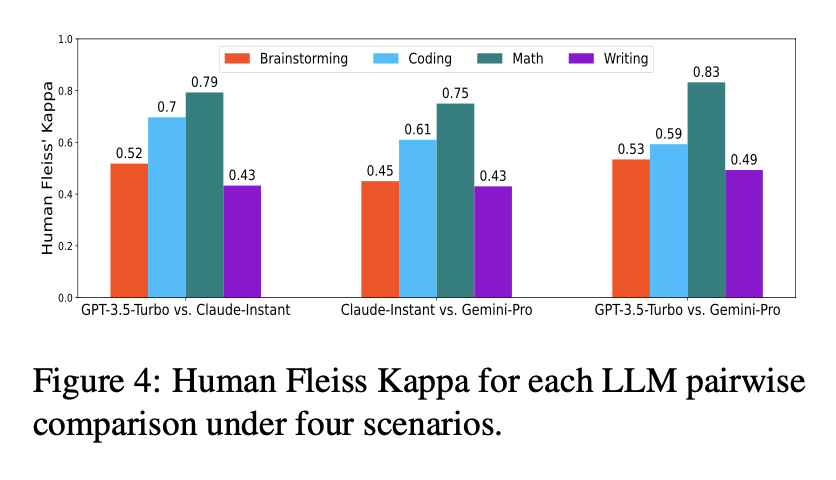
- 평가 시나리오: 브레인스토밍, 코딩, 수학, 글쓰기 (각각 40개 프롬프트 포함)
- 평가 기준: 도움이 되는 정도(Helpfulness), 해석 가능성(Interpretability), 논리적 추론(Reasoning), 창의성(Creativity)
- 대상 LLM: GPT-3.5-turbo, Claude-Instant, Gemini-Pro
인간 전문가 평가:
- 평가자: 카네기 멜론 대학교의 관련 전공자 7명
- 평가 방식: 3명의 평가자가 각 시나리오에서 30개의 비교 평가 수행 (총 120개 비교)
- 평가 기준: 0 (동등), 1 (응답 1 우세), 2 (응답 2 우세)
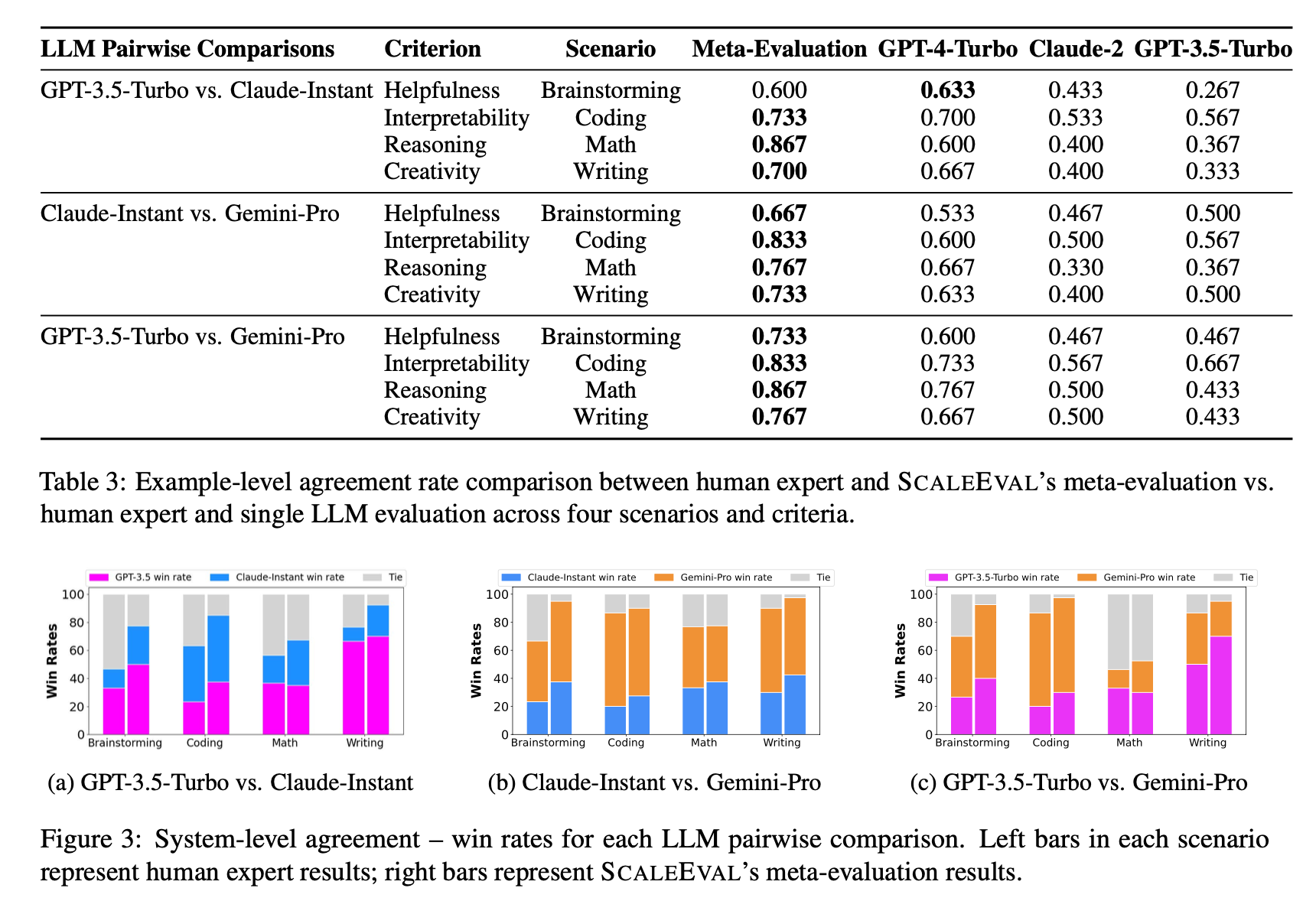
결과
- SCALEEVAL의 평가 결과는 인간 전문가 평가와 높은 상관관계를 가짐
- 예제 수준(example-level) 및 시스템 수준(system-level) 평가 일치율이 개별 LLM 평가자보다 더 높음
- 특히 코딩 및 수학과 같은 객관적인 평가 기준에서 높은 신뢰도를 보임
- LLM 간 비교 결과에서 GPT-3.5-turbo가 브레인스토밍, 수학, 글쓰기에서 우수, Gemini-Pro는 코딩에서 강세
결론:
다중 에이전트 토론 기반 평가 방식은 인간 전문가 평가와 높은 일치율을 보이며, 신뢰할 수 있는 메타 평가 방법으로 활용 가능함을 입증함.
7. 실험 II: LLM 평가자 vs. 메타 평가
목적
LLM을 평가자로 활용할 때, 평가 결과의 신뢰성을 분석하고 비용-성능 간의 균형을 비교함.
설정
- LLM 평가자: GPT-4-turbo, Claude-2, GPT-3.5-turbo, Auto-J (오픈소스 모델)
- 비교 대상 LLM: GPT-3.5-turbo, Claude-Instant, Gemini-Pro
- 평가 시나리오: 브레인스토밍, 코딩, 대화, 판단, 수학, 일반지식(ODG), 과학(ODS), 글쓰기
- 평가 기준: 도움이 되는 정도(Helpfulness), 해석 가능성(Interpretability), 논리적 추론(Reasoning), 창의성(Creativity)
바이어스 방지 조치:
- 응답의 순서(randomized order)를 무작위로 배치
- 평가자(LLM) 간 논의 순서도 무작위 설정
결과
- GPT-4-turbo가 전체적으로 가장 신뢰할 수 있는 평가자 (특히 브레인스토밍, 대화, 일반지식에서 우수)
- 코딩 평가에서는 Auto-J가 가장 높은 신뢰도를 보임 (GPT-4-turbo보다 저렴한 대안)
- GPT-3.5-turbo와 Claude-2도 특정 시나리오에서는 유사한 평가 신뢰도를 보임
- 비용 대비 성능 비교:
- GPT-4-turbo는 가장 높은 성능을 보였지만, API 비용이 비싸기 때문에 모든 작업에서 최적 선택은 아님
- 코딩, 판단, 글쓰기와 같은 일부 작업에서는 Claude-2 또는 Auto-J가 더 경제적인 선택일 수 있음
결론:
LLM을 평가자로 활용할 때, 단순히 성능이 가장 높은 모델(GPT-4-turbo)을 선택하는 것이 아니라, 비용 대비 신뢰도를 고려한 최적의 모델 선택이 필요함.
8. 실험 III: 평가 기준 프롬프트 변형에 따른 평가 신뢰도
목적
평가 기준 프롬프트의 표현 방식이 LLM 평가자의 평가 결과에 미치는 영향을 분석함.
설정
- 테스트 프롬프트 변형 5가지:
- 축약형(Shortened): 평가 기준을 간략화
- 무의미한 변형(Gibberish): 기준 문장을 무작위 문자로 대체
- 순서 변경(Shuffled): 평가 기준의 단어 순서를 무작위로 배치
- 반대로 변형(Flipped): 평가 기준을 거꾸로 배치 (예: "Not Helpful" → "lufpleH toN")
- 마스킹(Masked): 일부 단어를 마스킹하여 가려진 정보 제공
결과
- 마스킹된 기준(Masked)이 적용된 경우, 모든 LLM 평가자의 성능이 크게 저하됨
- 평가 기준의 핵심 설명을 제거하면 LLM 평가자들이 평가 수행을 거부하는 경우가 많음 (Claude-2에서 특히 두드러짐)
- GPT-4-turbo와 GPT-3.5-turbo는 변형된 기준에서도 상대적으로 일관된 평가 수행
- Claude-2는 기준이 변경되었을 때 평가 거부율이 높았으며, 평가 결과가 크게 흔들리는 경향을 보임
- LLM 평가자들은 평가 기준의 형식에 민감하며, 정보가 손실될 경우 평가 신뢰도가 낮아짐
결론:
LLM 평가자는 평가 기준 프롬프트의 표현 방식에 따라 평가 결과가 크게 달라질 수 있음. 따라서 일관된 평가 결과를 얻기 위해서는 명확하고 체계적인 평가 기준을 설정하는 것이 중요함.
Conclusion
본 연구에서는 SCALEEVAL이라는 확장 가능한 다중 에이전트 토론 기반 메타 평가 프레임워크를 제안하였다.
이 프레임워크는 기존 메타 평가 방식의 높은 비용과 시간 문제를 해결하며, 다양한 시나리오에서 신뢰할 수 있는 평가 결과를 제공한다.
핵심 결과
- SCALEEVAL은 인간 전문가 평가와 높은 상관관계를 보이며, 신뢰할 수 있는 메타 평가 방법으로 활용 가능함
- GPT-4-turbo가 가장 신뢰할 수 있는 평가자로 나타났지만, 비용 대비 성능을 고려해야 함
- 평가 기준 프롬프트의 표현 방식이 평가 결과에 큰 영향을 미칠 수 있음
향후 연구 방향
- 다중 에이전트 토론 방식을 더욱 정교하게 개선하여 평가 신뢰도를 높이는 연구 수행
- 다양한 LLM을 평가자로 활용할 수 있는 범용적 메타 평가 프레임워크 개발
- 평가 기준의 일관성을 유지하는 자동화된 방식 연구
본 연구에서 개발한 SCALEEVAL 프레임워크는 오픈 소스로 제공되며, 연구 커뮤니티가 자유롭게 활용하고 확장할 수 있다.